noiafobia = No Inteligencia Artificial Fobia
o
noaifobia = No Artificial Intelligence Fobia
noiafobia = No Inteligencia Artificial Fobia
o
noaifobia = No Artificial Intelligence Fobia
¿Recuerdas cuando estabas aprendiendo de máscaras de red? Seguro llegaste a pensar: “no sirven para nada”, “no las voy a necesitar”, “¿por qué inventaron esta locura?”. Además de sacarte una sonrisa espero convencerte de la enorme importancia que tienen en el gigantesco ecosistema de Internet.
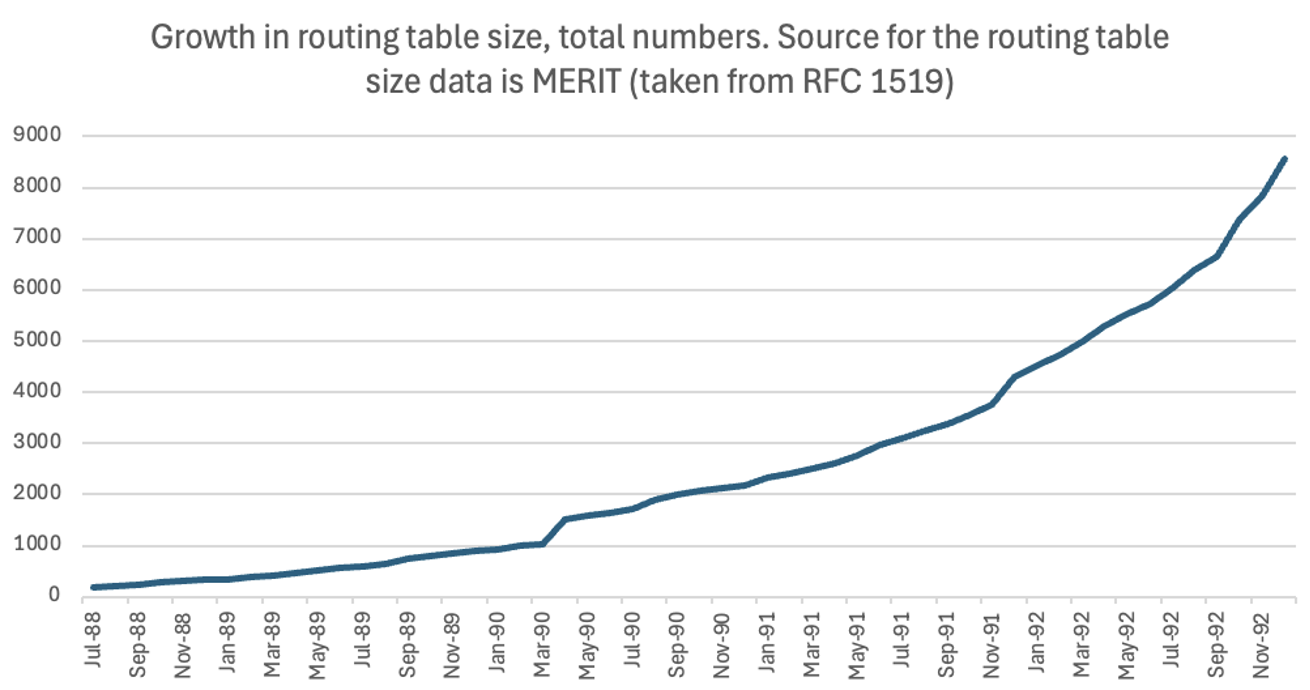
Este blog post resume la historia y los hitos relacionados detrás de los conceptos de máscara de red en el mundo de IPv4. Comenzamos la historia en un mundo donde no existían las clases (plano-flat), pasamos por un mundo classful y finalizamos en un Internet totalmente classless (CIDR). La información se basa en extractos de los RFC 790, 1338 y 1519, junto con hilos de correo electrónico de la lista de correo ‘Internet-history’.
Asumo que si llegaste a este documento si lo sabes :-) pero aquí va un mini concepto: una máscara de red se utiliza para ubicar y dividir un espacio de dirección de red y una dirección de host, en otras palabras, indica al sistema cuál es el esquema de particionamiento de subred.
Enrutamiento: Los enrutadores utilizan la máscara de red para determinar la porción de red y encaminar correctamente los paquetes.
Subnetting: Las máscaras de red se utilizan para crear redes más chicas.
Aggregación: Las máscaras de red permiten la creación de prefijos más grandes.
No, muy interesantemente no siempre existió la máscara de red, al comienzo las redes IP eran planas (flat) y siempre asumían 8 bits para la red y 24 bits para el host. En otras palabras, el primer octeto era la red, y los 3 octetos restantes corresponden al host. Otro aspecto llamativo es que hace muchos años también recibía el nombre de bitmask o solo mask (aún utilizado ampliamente).
Las clases no existieron hasta la aparición del RFC (septiembre 1981) de Jon Postel, es decir, incluso era una época antes de classless y classful.
La introducción del sistema classful fue impulsada por la necesidad de acomodar diferentes tamaños de red, ya que el ID de red original de 8 bits era insuficiente (256 redes). El sistema classful fue un intento de abordar las limitaciones de un espacio de direcciones plano, aunque este también tenía limitaciones de escalabilidad. En el mundo de las clases la máscara de red era implícita.
Si bien el sistema classful fue una mejora sobre el diseño original (plano), no era eficiente. Los tamaños fijos de los espacios de red y hosts de las direcciones IP llevaron al agotamiento del espacio de direcciones, especialmente con el creciente número de redes que eran más grandes que una Clase C, pero más pequeñas que una Clase B. Lo anterior llevó al desarrollo del enrutamiento Inter-Dominio Sin Clases (Classless Interdomain Routing – CIDR), que utiliza máscaras de subred de longitud variable (Variable Length Subnet Mask – VLSM).


El video muestra el funcionamiento del concepto "BGP Dynamic Capabilities" donde dos peers BGP pueden comunicarse sus capacidades "on the fly" sin interrupción de la sesión. El demo fue contruido con FRR hablando BGP sobre IPv6 y utilizamos como demostración la capacidad extended-nexthop la cual no es anunciada en el mensaje Open inicial. Un video enriquecedor que demuestra una vez más la enorme flexibilidad del protocolo BGP
Había una vez, en un mundo digital muy lejano conocido como Netland, un grupo de direcciones IP que estaban hartas de ser ignoradas. Eran las "modernas" direcciones IPv6, que, a pesar de su impresionante capacidad y flexibilidad, siempre se sentían opacadas por su predecesor, el venerable IPv4. Todo el mundo hablaba de él, y los routers lo adoraban. "¡Pero nosotros también somos geniales!", se quejaban las direcciones IPv6. "¡Es hora de mostrarles lo que valemos!"
Así que un día, decidieron organizar una fiesta épica para demostrar su relevancia, la llamaron la YottaFiesta en honor a que las megafiestas ya no son tan grandes 🙂 . Invitaron a todos los routers, switches, firewalls e incluso algunos servidores curiosos. La invitación decía: "¡Ven a la fiesta más grande del ciberespacio! Solo direcciones IPv6, pero no digas nada, ¡es una sorpresa!" Sabían que las loopback no podrían asistir porque no pueden salir de donde están, pero por si acaso, estaban oficialmente invitadas.
El problema fue que, en lugar de sencillamente enviar a los routers a la fiesta, las direcciones IPv6 se dieron cuenta de que no todos sabían cómo llegar. Como los routers estaban tan acostumbrados a trabajar con IPv4, se encontraron totalmente perdidos. "¿Cómo diablos llegamos a esa dirección con 128 bits?" se preguntaban. "¿Dónde está el next-hop para esta dirección?"
Mientras tanto, en otro rincón del mundo cibernético, RPKI intentaba asegurarse de que las rutas IP fueran seguras. Pero cada vez que trataba de verificar una dirección, se encontraba con un caos total. "¿Por qué hay tantas direcciones no válidas flotando por aquí? ¡Esto es un completo lío!" se lamentaba RPKI, mientras sacaba su llave de validación digital.
Sin embargo, NAT64, siempre buscando soluciones creativas, tenía un plan para hacer que IPv6 y IPv4 pudieran convivir. Decidieron crear una puerta secreta entre los dos mundos. Pero, en lugar de simplemente conectarlas, NAT64 y sus amigos decidieron hacer una broma. Se disfrazaron de direcciones IPv4 y comenzaron a enviar mensajes a los routers: "¡Hola! Soy una dirección IPv4, ven a mi fiesta, ¡en la famosa 192.168.1.1!"
Los routers, confiados de que era una dirección conocida, comenzaron a seguir las instrucciones al pie de la letra. Se pusieron sus mejores configuraciones, con el protocolo clásico de IPv4, y comenzaron a enrutar los paquetes hacia ese destino como si nada. Dentro de sí pensaban: "ojalá llegue un paquete IPv4 para enrutarlo de forma nativa en mi red IPv6 only con la elegancia del RFC 8950"
Pero al llegar al lugar, se encontraron con algo muy diferente. En lugar de la fiesta, lo que había era una revisión de seguridad en la puerta. RPKI, que estaba haciendo de portero, tenía instrucciones muy claras: "¡Solo pueden entrar direcciones IPv6 con ROAs válidos!"
Y justo detrás de él, el Firewall, implacable, no dejaba pasar ni a las direcciones bogon. Los pobres routers, que se pensaban que estaban a salvo con una dirección IPv4, fueron redirigidos a un portal que decía: "¡Feliz Día de los Inocentes! ¡Tú eres el verdadero inocente!"
Mientras tanto, RPKI observaba todo el caos y no podía evitar reírse: "Nunca más voy a confiar en estas direcciones traviesas. ¡Son más difíciles de rastrear que una ruta con ASNs descontrolados!" pensó mientras se ajustaba su sombrero de seguridad.
Y así, el mundo digital celebró ese Día de los Inocentes con risas, caos y un recordatorio muy importante: en el ciberespacio, las direcciones IP siempre tienen una sorpresa bajo la manga. ¡Nunca subestimes una IPv6 disfrazada de IPv4!
¡Feliz día de los inocentes!
Por Hugo Salgado y Alejandro Acosta
Introducción y planteamiento del problema
En el presente documento queremos discutir sobre un draft (borrador de trabajo para convertirse en un estándar) existente en IETF que llamó nuestra atención, es un documento que involucra dos mundos muy interesantes: IPv6 y DNS. Este draft introduce algunas mejores prácticas para el transporte de DNS sobre IPv6.
El draft se titula “DNS over IPv6 Best Practices” y se puede encontrar aquí.
¿De qué trata el documento y qué busca solucionar?
El documento describe un enfoque sobre cómo el Protocolo de Nombres de Dominio (DNS) debería transmitirse sobre IPv6 [RFC8200].
Se han identificado algunos problemas operativos al enviar paquetes de DNS a través de IPv6, el draft busca solucionar estos problemas.
Contexto técnico
El protocolo IPv6 exige un tamaño mínimo de unidad de transmisión (MTU) de 1280 octetos. Según la Sección 5 “Problemas de tamaño de paquete” del RFC8200, se establece que cada enlace en Internet debe tener un MTU de 1280 octetos o más. Si un enlace no puede transmitir un paquete de 1280 octetos en una sola pieza, se debe proporcionar el servicio de fragmentación y reensamblaje específicos del enlace en una capa inferior a IPv6.
Funcionamiento exitoso de PMTUD en un ejemplo adaptado a MTU de 1280 bytes
Imagen tomada de: https://www.slideshare.net/slideshow/naveguemos-por-internet-con-ipv6/34651833#2
Utilizando el Descubrimiento de MTU de Ruta (PMTUD) y la fragmentación en IPv6 (solo en el origen), se pueden enviar paquetes más grandes. Sin embargo, la experiencia operativa indica que enviar grandes paquetes de DNS sobre UDP en IPv6 resulta en altas tasas de pérdida. Algunos estudios -ya de muchos años, pero sirven de contexto- han encontrado que aproximadamente 10% de los routers en IPv6 descartan todos los fragmentos IPv6, y 40% de ellos bloquean los mensajes “Packet Too Big”, que hacen imposible la negociación de los clientes. (“M. de Boer, J. Bosma, ”Discovering Path MTU black holes on the Internet using RIPE Atlas”)
La mayoría de los protocolos de transporte modernos, como TCP [TCP] y QUIC [QUIC], incluyen técnicas de segmentación que permiten enviar flujos de datos más grandes sobre IPv6.
Un poco de historia
El Sistema de Nombres de Dominio (DNS) fue definido originalmente en los documentos RFC 1034 y RFC 1035. Está diseñado para funcionar sobre diferentes protocolos de transporte, incluyendo UDP y TCP, y más recientemente se ha extendido para operar sobre QUIC. Estos protocolos de transporte pueden utilizarse tanto en IPv4 como en IPv6.
Al diseñar el DNS, se estableció un límite en el tamaño de los paquetes DNS transmitidos por UDP a 512 bytes. Si un mensaje era más largo, se truncaba y se activaba el bit de Truncamiento (TC) para indicar que la respuesta estaba incompleta, permitiendo que el cliente intentara nuevamente con TCP.
Con este comportamiento original, UDP sobre IPv6 no excedía el MTU (unidad máxima de transmisión) del enlace IPv6, evitando problemas operativos por fragmentación. Sin embargo, con la introducción de las extensiones EDNS0 (RFC6891) se amplió el máximo hasta un teórico de 64KB, con lo que algunas respuestas superaban el límite de 512 bytes para UDP, lo que resultó en tamaños que podrían exceder el Path MTU, ocasionando conexiones TCP y afectó la escalabilidad de los servidores DNS.
Encapsulamiento de un paquete DNS en un frame ethernet
Hablemos de DNS sobre IPv6
DNS sobre IPv6 está diseñado para funcionar sobre UDP, así como TCP o QUIC. UDP solo proporciona puertos de origen y destino, un campo de longitud y una suma de verificación simple, y es un protocolo sin conexión. En contraste, TCP y QUIC ofrecen características adicionales como segmentación de paquetes, confiabilidad, corrección de errores y estado de conexión.
El funcionamiento de DNS sobre UDP en IPv6 es adecuado para tamaños de paquete pequeños, pero se vuelve menos confiable con tamaños más grandes, especialmente cuando se requiere fragmentación de datagramas IPv6.
Por otro lado, DNS sobre TCP o QUIC en IPv6 funciona bien con todos los tamaños de paquete. Sin embargo, el uso de un protocolo con estado como TCP o QUIC exige más recursos del servidor DNS (y otros equipos como Firewall, DPIs, IDS, etc), lo que puede afectar la escalabilidad. Esta puede ser una compensación razonable para servidores que necesitan enviar paquetes de respuesta DNS más grandes.
La sugerencia del draft en cuanto a DNS sobre UDP recomienda limitar el tamaño de los paquetes de DNS sobre UDP en IPv6 a 1280 octetos. Esto evita la necesidad de fragmentación IPv6 o el descubrimiento del MTU del camino (Path MTU Discovery), lo que asegura una mayor confiabilidad.
La mayoría de las consultas y respuestas DNS encajarán dentro de este límite de tamaño de paquete y, por lo tanto, se pueden enviar a través de UDP. Los paquetes DNS más grandes no deben enviarse por UDP; en su lugar, deben ser enviados a través de TCP o QUIC, como se menciona en la siguiente sección.
DNS sobre TCP y QUIC
Cuando se necesitan transportar paquetes DNS más grandes, se recomienda utilizar DNS sobre TCP o QUIC. Estos protocolos manejan la segmentación y ajustan de manera confiable su tamaño de segmento para diferentes valores de MTU del enlace y del camino, lo que los hace mucho más fiables que el uso de UDP con fragmentación IPv6.
La sección 4.2.2 del [RFC1035] describe el uso de TCP para transportar mensajes DNS, mientras que el [RFC9250] explica cómo implementar DNS sobre QUIC para proporcionar confidencialidad en el transporte. Además, los requisitos operativos para DNS sobre TCP están descritos en el [RFC9210].
Seguridad
El cambio de UDP a TCP/QUIC para respuestas grandes implica que el servidor DNS debe mantener un estado adicional para cada consulta recibida a través de TCP/QUIC. Esto consumirá recursos adicionales en los servidores y afectará la escalabilidad del sistema DNS. Además, esta situación puede dejar a los servidores vulnerables a ataques de Denegación de Servicio (DoS).
¿Esta es la manera correcta?
A pesar de que sí creemos que esta solución aportará muchos beneficios al ecosistema de IPv6 y DNS, se trata de un parche operativo temporal, pero que no resuelve la solución de raíz.
Creemos que la solución correcta es que la fragmentación en el origen funcione, que PMTUD no se encuentre roto en el camino, y que las cabeceras de fragmentación sean permitidas por los dispositivos de seguridad. Esto requiere de cambios en distintos actores de Internet que puede tomar bastante tiempo, pero no por eso debemos abandonar la educación y los esfuerzos por lograr hacer lo correcto.
Luego de usar el reporte de “World Happiness Report y las estadísticas de penetración de IPv6 de google me he conseguido que existe un grado...

