Mostrando entradas con la etiqueta internet. Mostrar todas las entradas
Mostrando entradas con la etiqueta internet. Mostrar todas las entradas
sábado, 5 de julio de 2025
martes, 28 de enero de 2025
¿Qué historia hay detrás de las famosas máscaras de red?
Introducción
¿Recuerdas cuando estabas aprendiendo de máscaras de red? Seguro llegaste a pensar: “no sirven para nada”, “no las voy a necesitar”, “¿por qué inventaron esta locura?”. Además de sacarte una sonrisa espero convencerte de la enorme importancia que tienen en el gigantesco ecosistema de Internet.
Objetivo
Este blog post resume la historia y los hitos relacionados detrás de los conceptos de máscara de red en el mundo de IPv4. Comenzamos la historia en un mundo donde no existían las clases (plano-flat), pasamos por un mundo classful y finalizamos en un Internet totalmente classless (CIDR). La información se basa en extractos de los RFC 790, 1338 y 1519, junto con hilos de correo electrónico de la lista de correo ‘Internet-history’.
¿Sabes lo que es la máscara de red?
Asumo que si llegaste a este documento si lo sabes :-) pero aquí va un mini concepto: una máscara de red se utiliza para ubicar y dividir un espacio de dirección de red y una dirección de host, en otras palabras, indica al sistema cuál es el esquema de particionamiento de subred.
¿Cuál es el propósito de la máscara de red?
Enrutamiento: Los enrutadores utilizan la máscara de red para determinar la porción de red y encaminar correctamente los paquetes.
Subnetting: Las máscaras de red se utilizan para crear redes más chicas.
Aggregación: Las máscaras de red permiten la creación de prefijos más grandes.
¿Siempre han existido las máscaras de red?
No, muy interesantemente no siempre existió la máscara de red, al comienzo las redes IP eran planas (flat) y siempre asumían 8 bits para la red y 24 bits para el host. En otras palabras, el primer octeto era la red, y los 3 octetos restantes corresponden al host. Otro aspecto llamativo es que hace muchos años también recibía el nombre de bitmask o solo mask (aún utilizado ampliamente).
Lo anterior conlleva a que no siempre existieron las clases (A, B, C, D)
Las clases no existieron hasta la aparición del RFC (septiembre 1981) de Jon Postel, es decir, incluso era una época antes de classless y classful.
La introducción del sistema classful fue impulsada por la necesidad de acomodar diferentes tamaños de red, ya que el ID de red original de 8 bits era insuficiente (256 redes). El sistema classful fue un intento de abordar las limitaciones de un espacio de direcciones plano, aunque este también tenía limitaciones de escalabilidad. En el mundo de las clases la máscara de red era implícita.
Las clases tampoco solucionaron todo
Si bien el sistema classful fue una mejora sobre el diseño original (plano), no era eficiente. Los tamaños fijos de los espacios de red y hosts de las direcciones IP llevaron al agotamiento del espacio de direcciones, especialmente con el creciente número de redes que eran más grandes que una Clase C, pero más pequeñas que una Clase B. Lo anterior llevó al desarrollo del enrutamiento Inter-Dominio Sin Clases (Classless Interdomain Routing – CIDR), que utiliza máscaras de subred de longitud variable (Variable Length Subnet Mask – VLSM).

Extracto del RFC 790
¿Sabías que no siempre la máscara se escribió con bits continuos encendidos de izquierda a derecha?
Al comienzo en la máscara de red no debía “encenderse” bit a bit de izquierda a derecha, es decir, máscaras como: 255.255.192.128 era completamente válidas. Esta configuración era aceptada por routers (IMPs -los primeros routers-) y diferentes sistemas operativos, entre ellos los BSDs y SunOSs antiguos. Es decir, hasta comienzos de los 90’s aún era posible tener máscaras de red de bits no continuos.
¿Por qué se decidió que los bits luego fueran obligatoriamente encendidos de izquierda a derecha?
Existieron varias razones, la principal tiene que ver con enrutamiento y el famoso concepto “longest match” que conocemos donde el router selecciona la ruta cuya máscara de subred sea la más larga que coincida con la dirección de destino del paquete. Es decir, si los bits no son continuos se crea una complejidad computacional muy alta. En resumen: eficiencia.
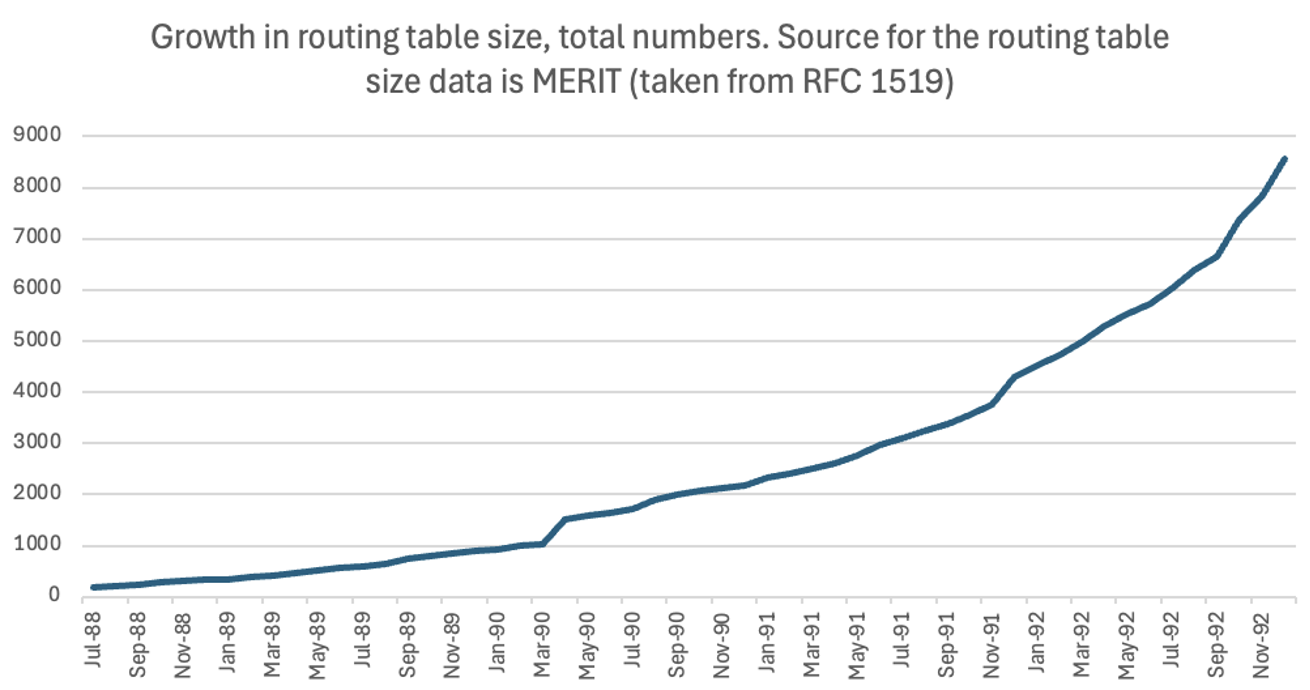
Desde esa época ya se agotaban direcciones IPv4
El agotamiento de recursos IPv4 no es algo nuevo, incluso en la primera sección del RFC 1338 en su numeral uno hace referencia al agotamiento de la Clase B indicando que la Clase C es demasiado pequeña para muchas organizaciones, y la Clase B es demasiado grande. Esto ocasionó una presión sobre el espacio de direcciones Clase B, agotando la misma. Y no solo eso, el mismo RFC en el numeral 3 cita textualmente: “Eventual exhaustion of the 32-bit IP address space” (1992).
CIDR aborda las soluciones de ayer, que se convirtieron en los problemas de ese momento
Al momento de crear las clases se crearon más redes lo que conlleva a más prefijos y a su vez mayor consumo de memoria y CPU. Por ello en septiembre de 1993 en el RFC 1519 apareció el concepto de CIDR, trayendo consigo soluciones a algunas situaciones, entre ellas, poder hacer supernetting (es decir, poder apagar bits de derecha a izquierda) e intentar reducir la cantidad de prefijos de red. Es importante destacar que el RFC 1338 también mantuvo conceptos similares.
Finalmente, la notación de prefijo (/nn) también aparece gracias a CIDR lo que se hace posible una vez más gracias a la continuidad de los bits encendidos y apagados de la máscara de red.
En resumen, el objetivo de CIDR era enlentecer el crecimiento de las tablas de enrutamiento y buscar ser más eficientes en la utilización del espacio de direcciones IP.
Timeline

Conclusiones
El concepto de máscara de red ha evolucionado notablemente desde su origen, desde su no-existencia en un esquema plano (flat), luego rígido a un modelo flexible con CIDR. Inicialmente, las redes classful y las máscaras discontinuas generaban ineficiencia y problemas de escalabilidad a medida que Internet crecía.
Un cambio clave fue la exigencia de continuidad en los bits encendidos, lo que simplificó el proceso de selección de rutas y permitió a los routers operar más eficientemente.
Este documento informativo resalta los hitos clave y las motivaciones detrás de la evolución del direccionamiento IP y enfatiza la importancia de comprender el contexto histórico para apreciar plenamente la arquitectura actual de Internet.
Referencias
RFC https://datatracker.ietf.org/doc/html/rfc1338
RFC https://datatracker.ietf.org/doc/html/rfc1380
RFC https://datatracker.ietf.org/doc/html/rfc1519
RFC https://datatracker.ietf.org/doc/html/rfc790
Hilo de la lista de correo de ISOC “Internet History” llamado “The netmask”: https://elists.isoc.org/pipermail/internet-history/2025-January/010060.html
viernes, 8 de marzo de 2024
BGP Stream: un año de análisis sobre incidentes BGP
BGP Stream: un año de análisis sobre incidentes BGP
04/03/2024
Por Alejandro Acosta, Coordinador de I+D en LACNIC
LACNIC presenta la primera página on line que muestra los incidentes y el análisis de datos de medición del Border Gateway Protocol (BGP) en América Latina y el Caribe.
PRINCIPALES SUCESOS. Además de sumarizar la información se aprecian los tres principales sucesos, los cuales son: posibles secuestros de red, interrupciones BGP y fugas de rutas.
Posibles secuestros de red es la adquisición ilegítima de grupos de direcciones IP al corromper las tablas de enrutamiento de Internet. Tradicionalmente ocurre cuando el Sistema Autónomo anuncia un prefijo que no le pertenece.
Interrupciones (outages) se refiere a la pérdida de visibilidad de prefijos de red por un grupo mayoritario de sensores[1] .
Fugas de rutas como su nombre lo indica, se refiere al anuncio -posiblemente- no intencional de algún prefijo de red vía BGP. Por ejemplo, un peering privado de intercambio de tráfico, alguno de los participantes anuncia el prefijo del peer a Internet. Este caso es el más difícil de detectar por los algoritmos y no consigue identificar algunas de éstas incidencias.
¿Cómo se obtienen los datos?
Esta iniciativa utiliza BGP Stream de Cisco, un proceso automatizado que selecciona los incidentes más grandes e importantes, qué tipo de situación es y cuáles ASNs están involucrados.
Leer también:
La información se publica de forma abierta ya que LACNIC considera que se trata de información importante para que ingenieros, responsables de redes y organizaciones puedan conocer los incidentes más comunes de la región y crear conciencia sobre la situación.
Ello permite la investigación eficiente de eventos, creación rápida de prototipos y de herramientas complejas y aplicaciones de monitoreo a gran escala (por ejemplo, detección de interrupciones de conectividad, ataques o secuestros de BGP).
En base a un sistema desarrollado por el área de I+D de LACNIC, se obtienen los datos de forma cruda, los parcela, identifica, limpia y almacena en una base de datos para posteriormente generar estadísticas y gráficas. Lo anterior ocurre cada 24 horas de forma automatizada.
RESULTADOS. Durante el período de tiempo estudiado -febrero 2023 a febrero 2024- nos encontramos con los siguientes resultados que se muestran en la siguiente gráfica comparando eventos BGP mundiales vs eventos BGP de nuestra región.
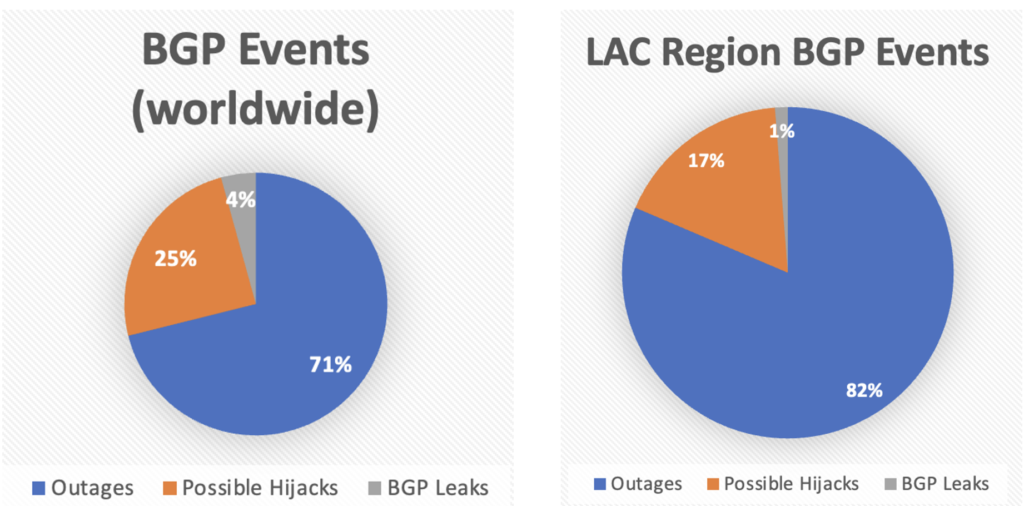
Comparando la gráfica mundial versus la gráfica de la región vemos que el orden de incidentes es similar (el mayor es outages, seguido por posibles secuestros de red y finalizando en fugas de prefijos). Adicionalmente hay que destacar que en nuestra región las interrupciones (outages) son más frecuentes en comparación con el total mundial de eventos BGP.
Al analizar la tabla resultados mostrando eventos BGP Mundiales vs eventos BGP de nuestra región, nos encontramos con los siguientes fatos.
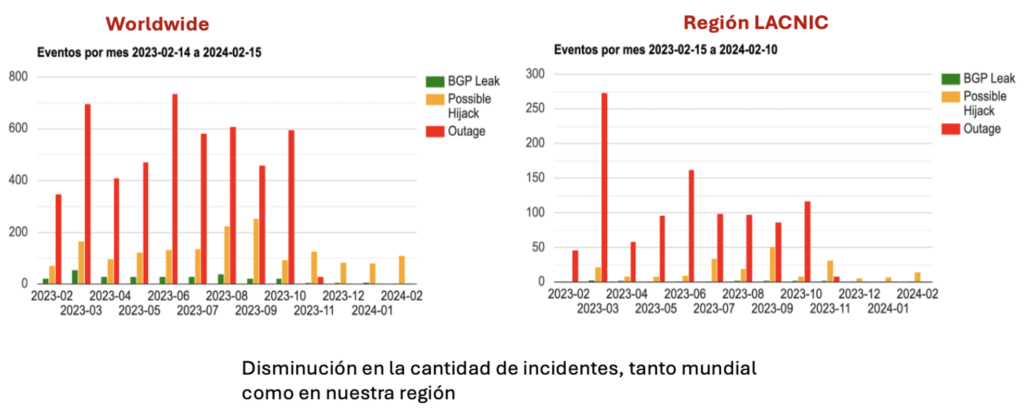
TOP 5 países de nuestra región con Interrupciones BGP (Outages)
| Outages | |
| CC | Events |
| BR | 781 |
| AR | 99 |
| HT | 24 |
| MX | 22 |
| CL | 17 |
TOP 5 países de nuestra región con secuestros de prefijos (Possible Hijacks)
| Expected CC | Detected CC | Events |
| BR | BR | 67 |
| BR | none | 35 |
| PY | BR | 24 |
| BR | US | 22 |
| BR | CN | 9 |
TOP 3 países de nuestra región con fugas de rutas (Route Leaks)
| Origin CC | Leaker CC | Events |
| VE | VE | 7 |
| MX | MX | 5 |
| CL | PA | 2 |
El impacto
En este primer año de funcionamiento desde LACNIC hemos observado una disminución de los incidentes BGP, entre los motivos de estos resultados podemos identificar: a) el despliegue y la adopción de Sistema de Certificación de Recursos (RPKI), b) el Registro de Enrutamiento de Internet de LACNIC (IRR) y la adopción del RFC 9234 (Roles en BGP).
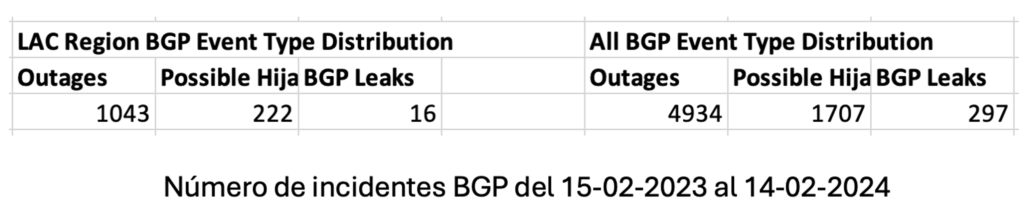
La adopción de dichas herramientas se está dando por mejores prácticas de los operadores y el impulso de MANRS por ISOC.
Conclusiones
Los posibles secuestros de red (BGP Hijacks), interrupciones BGP (Outages) y fugas de rutas son los incidentes BGP más comunes. Durante el primer año de recopilación de datos, se observa una disminución de estos casos; sin embargo, en el futuro cercano no desaparecerán por completo. Es crucial implementar medidas robustas de redundancia y resiliencia en las redes, así como detectar y prevenir tempranamente posibles secuestros para garantizar la integridad y confiabilidad de las rutas de Internet.
En LACNIC, buscamos crear conciencia y motivar a los ISPs y organizaciones a estar preparados para abordar estos incidentes de manera eficiente cuando ocurran.
Referencias
https://stats.labs.lacnic.net/BGP/bgpstream-lac-region.html
miércoles, 28 de junio de 2023
martes, 8 de febrero de 2022
El Metaverso será posible gracias al IPv6
El Metaverso promete ser uno de los desarrollos tecnológicos que mayor impacto traerá en el futuro las formas de uso y consumo en Internet[1].
Aunque por ahora la promesa de Mark Zuckerberg sigue siendo un poco gaseosa y el uso práctico en la actualidad se reduce a la comunidad de los denominados “GAMERS”, el desarrollo, masificación y despliegue del denominado “Metaverso” será posible gracias a la tecnología que soporta el protocolo IPv6[1].
¿Por qué el IPV6 es tan importante para el Desarrollo del Metaverso?
Por: Gabriel E. Levy B. y Alejandro Acosta
www.galevy.com – blog.acostasite.com
En su casi medio siglo de vida los protocolos TCP/IP han servido para conectar a miles de millones de personas.
Desde la creación de Internet, han sido los estándares universales sobre los cuales se transmite la información por la red, haciendo posible que Internet funcione[3].
La sigla IP puede referirse a dos conceptos vinculados entre ellos; El primero es un protocolo (Internet Protocol – Protocolo de Internet en Español) y su principal función es el uso bidireccional (origen y destino) de transmisión de datos basado en la norma OSI (Open System Interconnection)[4].
La segunda posible referencia cuando se habla de IP, está vinculada a una asignación numérica de direcciones físicas conocida como Dirección IP, un identificativo lógico y jerárquico asignado a una interfaz de un dispositivo dentro de una red que utilice el protocolo de Internet (Internet Protocol – IP), la cual corresponde al nivel de red o nivel 3 del modelo de referencia OSI.
IPv4 hace referencia al Protocolo de Internet en su cuarta versión (en inglés, Internet Protocol version 4, IPv4), un estándar de interconexión de redes basados en Internet, y que fue implementado en 1983 para el funcionamiento de ARPANET y la posterior migración a Internet[5].
El IPv4 usa direcciones de 32 bits, equivalentes a 4.2 mil millones de bloques de numeración únicas, una cifra que, para la década de los años 80 parecía sencillamente inagotable, no obstante, y por el crecimiento enorme e inesperado de Internet, para el año 2011 pasó lo que nunca se creyó que fuera a ocurrir, todas las direcciones se agotaron[6].
IPv6 como solución al Cuello de botella
Para solucionar la falta de direcciones disponibles, conocido como “RECURSOS”, los grupos de ingeniería responsables de Internet, han recurrido a múltiples soluciones que van desde la creación de subredes privadas, de tal forma que con una misma dirección se puedan conectar múltiples usuarios, hasta la creación de un nuevo protocolo denominado IPv6 que promete ser la solución definitiva del problema y el cual fue lanzado oficialmente el 6 de junio de 2012[7]:
“Previendo el agotamiento de la dirección disponibles en IPv4 y como una solución de largo plazo, el organismo que se encarga de la estandarización de los protocolos de Internet (IETF, Internet Engineering Task Force), diseñó una nueva versión del Protocolo de Internet, concretamente la versión 6 (IPv6), con una casi inagotable disponibilidad, a partir de una nueva longitud de 128 bits, es decir alrededor 340 sextillones de direcciones”[8].
Es importante aclarar que la creación del protocolo IPv6, no implica una migración, es decir un cambio de un protocolo a otro como si fuera un proceso de remplazo, sino que se diseñó un mecanismo que permite por un tiempo la coexistencia articulada de ambos protocolos.
Para garantizar una transición transparente para los usuarios y que garantice un tiempo prudencial para que los fabricantes incorporen la nueva tecnología y los proveedores de Internet la implementen en sus propias redes, la organización encargada de la estandarización de los protocolos de Internet (IETF, Internet Engineering Task Force), diseñó junto con el mismo protocolo IPV6, una serie de mecanismos que se denominan de transición y coexistencia.
“Es como una balanza, en la que hoy en día el lado con el mayor peso representa el tráfico IPv4, pero poco a poco, gracias a esta coexistencia, conforme más contenidos y servicios estén disponibles con IPv6, el peso de la báscula irá hacia el otro lado, hasta que IPv6 sea predominante. Esto es lo que llamamos la transición”[9].
El diseño del protocolo IPv6 da preferencia a IPv6 frente a IPv4, si ambos están disponibles (IPv4 e IPv6). De ahí que se produzca ese desplazamiento del peso en “nuestra balanza”, de una forma natural, en función de múltiples factores, y sin que podamos determinar durante cuánto tiempo seguirá existiendo IPv4 en la Red y en qué proporciones. Posiblemente podamos pensar, intentando mirar en la bola de cristal, que IPv6 llegará a ser predominante en 3-4 años, y en ese mismo entorno de tiempo, IPv4 desaparecerá de Internet, al menos en muchas partes de ella” [10].
Sin IPv6 quizás no haya metaverso
Cómo lo analizamos en pasados artículos, los Metaversos o Metauniversos, son entornos donde los humanos interactúan social y económicamente como iconos, a través de un soporte lógico en un ciberespacio, como una metáfora amplificada del mundo real, pero sin las limitaciones físicas o económicas[11].
“Puedes pensar en el Metauniversos como una Internet encarnada.
En lugar de ver contenido, estás en él y te sientes presente con otras personas como si estuvieras en otros lugares teniendo diferentes experiencias que no podrías tener en una aplicación 2D o página web“. Mark Zuckerberg Ceo de Facebook[12].
El Metaverso necesariamente “corre” o se “Ejecuta” sobre Internet, que a su vez utiliza el IP o (Internet Protocol) para funcionar.
El Metaverso es un tipo de simulación que mediante “Avatares” permite a los usuarios tener conexiones mucho más inmersivas y realistas, desplegando un universo virtual que corre en línea, razón por la cual se hace necesario garantizar que el Metaverso sea Inmersivo, multisensorial, Interactivo, que corran en tiempo real, que permitan diferenciar de manera precisa a cada usuario, que despliegue herramientas gráficas simultáneas y complejas, entre muchos otros elementos, que simplemente sería imposible de garantizar sobre el Protocolo IPv4, puesto que ni existen suficientes “Recursos IP” para cada conexión, ni es posible garantizar que con tecnologías como el NAT pueda correr adecuadamente.
Los elementos claves:
- El IPV6 es el único protocolo puede garantizar la cantidad suficiente de “Recursos IP” para soportar el Metaverso.
- El IPV6 evita el mecanismo de NAT en las redes que complicaría tecnológicamente el despliegue del Metaverso.
- El RTT/Delay de los enlaces de IPv6 es mucho menor que el de IPv4, permitiendo que las representaciones gráficas de los “avatares”, incluyendo los hologramas puedan desplegarse de forma sincrónica.
- Teniendo en cuenta la alta cantidad de datos que implica el despliegue del Metaverso, es necesario garantizar la menor perdida de datos posible, razón por la cual el IPv6 se convierte en la mejor opción pues la evidencia muestra que la pérdida de datos es un 20% menor que la de IPv4[13].
El Rol de los Pequeños ISP
Teniendo en cuenta que los pequeños ISP son los grandes responsables de la conectividad de millones de personas en las regiones más apartadas de todo Latinoamérica y como lo hemos analizado anteriormente, son los grandes responsables de la disminución de la Brecha Digital[14], es muy importante que estos operadores aceleren el proceso de migración hacia IPV6, no solamente para ser más competitivos frente a sus grandes competidores, sino para que puedan garantizarle a sus usuarios que tecnologías como El Metaverso funcionarán en sus dispositivos sin mayores traumatismos tecnológicos.
En Conclusión, si bien aún es incierto el alcance real que tendrá El Metaverso, su despliegue, implementación y masificación será posible gracias al Protocolo IPv6, una tecnología que ha dado solución a la disponibilidad de los recursos IP, evitando el engorroso procedimiento de la traducción de NAT, mejorando los tiempos de respuesta, disminuyendo el RTT o Delay y evitando la perdida de muchos paquetes, al tiempo que facilitará la simultaneidad de usuarios.
Todo lo anterior nos permite afirmar que El Metaverso sin IPv6, no sería posible.
Descargo de Responsabilidades: Este artículo corresponde a una revisión y análisis en el contexto de la transformación digital en la sociedad de la información, y está debidamente soportado en fuentes académicas y/o periodísticas confiables y verificadas, las cuales han sido demarcadas y publicadas.
La información que contienen este artículo periodístico y de opinión, no necesariamente representa la postura de Andinalink, o las entidades con las que desarrolla sus relaciones comerciales.
[1] Artículo Andinalink: Metaversos y el Internet del Futuro
[2] Artículo Andinalink: Metaversos: Expactativas VS Realidad
[3] En el artículo: El agotamiento del protocolo IP explicamos las características del protocolo TCP: El Agotamiento del Protocolo IP
[4] Documento estándar de referencia sobre el Modelo de conectividad OSI
[5] En el artículo: ¿Fue creada Arpanet para soportar una guerra nuclear?, se detalla las características e historia de Arpanet.:
[6] Documento de Lacnic sobre las fases del agotamiento de IPV4
[7] Documento de IETF sobre el lanzamiento oficial de IPV6 en su sexto aniversario
[8] Guía de referencia de Transición de IPV6 de Mintic Colombia
[9] Guía de referencia de Transición de IPV6 de Mintic Colombia
[10] Guía de referencia de Transición de IPV6 de Mintic Colombia
[11] Artículo Andinalink sobre los Metaversos
[12] MARK IN THE METAVERSE: Facebook’s CEO on why the social network is becoming ‘a metaverse company: The Verge Podcast
[13] Análisis de Alejandro Acosta de LACNIC, sobre el impacto del IPV6 en sistemas táctiles.
[14] Artículo Andinalink: Los Wisp disminuyen la brecha digital
martes, 28 de julio de 2020
¿Fue creada Arpanet para soportar una guerra nuclear?
Ya sea en una clase del colegio o incluso la universidad, un documental en televisión o un apunte anecdótico en alguna revista de tecnología, en algún momento de nuestras vidas hemos escuchado que Arpanet, la red predecesora de Internet, nació como un proyecto informático capaz de soportar las consecuencias de una guerra nuclear, incluso si se hace una sencilla búsqueda en google escribiendo la frase: “TCP/IP Arpanet” entre las opciones desplegadas aparecerá como resultado “tcp/ip arpanet nuclear war”.
¿Es cierto que Arpanet tuvo un propósito militar antinuclear?
Por: Gabriel E. Levy B.(www.galevy.com) y Alejandro Acosta (Lacnic) – Artículo conjunto promovido por Andinalink y Lacnic
Advanced Research Projects Agency Network (ARPANET), fue la primera red de datos de computadora – WAN -, que funcionó basada en un sistema de intercambio de paquetes de información conocido como “packet-switching”, y que se consolidó en este propósito a través de un protocolo denominado TCP, que en esencia permite la fragmentación de la información en múltiples paquetes, siendo estas dos tecnologías el origen de lo que hoy conocemos como “Internet”[1].
De acuerdo a los registros históricos disponibles y los relatos de sus creadores, la idea o concepto de una red de ordenadores con capacidad para comunicar usuarios ubicados en computadoras, distantes de forma remota entre ellas, fue formulado en abril de 1963 por Joseph C. R. Licklider[2], quien es considerado uno de los padres de la ciencia de la computación y quien trabajando de la mano de Bolt, Beranek y Newman (BBN)[3]una compañía especializada en investigación y desarrollo de tecnología de punta, elaboraron de manera conjunta un documento que proponía la creación de una gran sistema de interconexión de computadoras, que en su momento llamaron,“La red galáctica”[4].
Una proyecto financiado por el Departamento de Defensa de los Estados Unidos – DOT
La Agencia de Proyectos de Investigación Avanzados de Defensa, más conocida por su acrónimo DARPA, (Defense Advanced Research Projects Agency)[5], es una agencia adscrita al Departamento de Defensa de los Estados Unidos de Norte America y es la responsable en gran medida, del desarrollo de nuevas tecnologías enfocadas en uso militar[6].
En Octubre de 1963, Darpa (para ese momento se llamaba ARPA), convocó a Joseph C. R. Licklider[7] para presentar los resultados de su investigación, lo cual le permitió de paso convencer a los científicos de computación Ivan Sutherland y Robert «Bob» Taylor[8], acerca de la importancia y los alcances de sus investigaciones, pero más importante aún, de la necesidad de crear una gran red de computadoras[9].
Como director de Información del – Information Processing Techniques Office – IPTO – de ARPA, y convencido del trabajo liderado por Licklider, el informáticoRobert «Bob» Taylor,planteó al entonces director de ARPA Charles Herzfeld, la posibilidad de conectar entre sí las computadoras que hacían parte del Departamento de Defensa de Los Estados Unidos, buscando optimizar los recursos y el flujo de Información.
“Robert Taylor, tuvo una brillante idea basada en las ideas propuestas por J. C. R. Licklider : ¿Por qué no conectar todos esos ordenadores entre sí? Al construir una serie de enlaces electrónicos entre diferentes máquinas, los investigadores que estuvieran haciendo un trabajo similar en diferentes lugares del país podrían compartir recursos y resultados más fácilmente” Análisis publicado por @Wicho en el portal Microsiervos[10]
Uno de los aspectos más relevantes de la apuesta de Taylor, es que no se concentró exclusivamente en la interconexión y la compartición de recursos, sino que desde el principio buscó garantizar la interoperabilidad entre los diferentes tipos de máquinas, sin importar la compatibilidad entre ellas, creando de paso una protección contra fallos, algo que solo podría lograr si la estructura de la red estaba descentralizada, de esta forma si un ordenador fallaba, los demás podrían seguir trabajando[11]. La idea en su conjunto le encantó Herzfeld, quien asignó un presupuesto inicial de un millón de dólares (Equivalente a 8 Millones de dólares al tiempo presente) para el desarrollo de esta red descentralizada y aprueba de fallos por problemas de interoperabilidad.
De acuerdo con una entrada correspondiente al mes de marzo de 1964, en la cronología de Internet que mantiene Larry Roberts, “El trabajo conjunto de los investigadores del MIT, junto con el aporte de de Licklider, Kleinrock y Roberts, permitió que el proyecto de Arpanet tomara fuerza”[12].
Como parte de esta indagación, en un cruce de correos sostenidos entre Alejandro Acosta coautor de este artículo y Vint Cenf, científico computacional de Stanford que hizo parte del proyecto de Arpanet, existe una referencia a Larry Roberts en donde asegura que:
“Tenía claro que ARPANET estaba destinado al apoyo de recursos, es decir, una red diseñada para compartir “.
Cazando el Mito
The RAND Corporation, a principios de la década de los 60 y en el contexto de plena guerra fría[13], comenzó a trabajar en el diseño de un tipo de red segura de comunicaciones capaz de sobrevivir a un ataque con armas nucleares, con fines militares. Al frente de esta Investigación se encontraba Paul Baran[14] quien propuso en un documento presentado en 1962 y publicado en 1964, “El uso de una red descentralizada con múltiples caminos entre dos puntos; en donde la división de mensajes completos en fragmentos seguiría caminos alternativos y la red estaría capacitada para responder ante sus propios fallos”[15].
Para 1964 el profesor Leonard Kleinrock, profesor de la Universidad de UCLA en California[16], escribió un libro denominado Communication Nets[17], en el cual propuso la teoría de conmutación de paquetes en la interconexión de redes, las cuales en 1968 fueron comparadas con las investigaciones que venían desarrollando en el mismo sentido Paul Baran y Donald Davies,
“quienes llegaron independientemente a conclusiones similares a las de Kleinrock[18]” y que en conjunto sirvieron como inspiración para el desarrollo de la arquitectura descentralizada de Arpanet, aunque si bien existe mucha literatura, es imposible determinar con total certeza cuál fue el nivel de influencia de la investigación de Baran sobre el diseño final del modelo propuesto por el MIT.
Un año después, a las 10.30 de la noche del día 29 de octubre de 1969, el mismo profesor Leonard Kleinrock desde su computadora SDS Sigma 7, envió el mensaje LOGIN al equipo SDS 940 del instituto de investigación de Stanford. El mensaje quedó recortado a un extraño “lo”, ya que hubo un fallo de transmisión, pero una hora después la máquina de Stanford recibió la palabra “Login” completa, produciéndose de esta forma la primera conexión entre computadores dando formalmente origen práctico a la red: ARPANET, que en menos de dos años ya tenía más de 70 computadoras conectadas[19]. Por su parte el protocolo TCP apareció unos años después, pero no sería perfeccionado sino hasta principio de los años 80 [20]
La influencia de Baran en el proyecto
Si bien los diseños originales de Paul Baran tenía un claro propósito Militar para garantizar la supervivencia del sistema de interconexión ante un ataque nuclear y aunque el proyecto de Arpanet fue financiado por el Departamento de Defensa de los Estados Unidos a través de DARPA, la imposibilidad para determinar a ciencia cierta el nivel de influencia que tuvo los estudios de Baran sobre el diseño final y al no haber existido una solicitud puntual a los investigadores sobre el diseño de una red que tuviera estas características, (de acuerdo a sus propias afirmaciones), NO es posible asegurar que el diseño descentralizado de ARPANET tuvo un propósito relacionado con la supervivencia Nuclear, siendo este un MITO ampliamente difundido a lo largo de la historia.
No obstante lo anterior, es importante hacer salvedad en varios aspectos claves, por una parte el mito tiene origen en hechos históricos demostrables que justifican coherentemente el supuesto que lo subyace. El primero de ellos es que la financiación militar del proyecto estuvo a cargo del Departamento de Defensa de los Estados Unidos mediante DARPA, que se dió en el contexto de la guerra fría en un momento en que el espionaje era una de las mayores preocupaciones del gobierno, por lo que la confidencialidad del mismo y el secreto que lo enmarca, sin duda jugaron un rol preponderante para que las verdaderas intenciones posiblemente fueran clasificadas. Finalmente las investigaciones de Paul Baran de una u otra forma pudieron influir en el resultado final del proyecto, lo cual podría ocasionar que sin quererlo, los investigadores del MIT (Instituto Tecnológico de Massachuset) terminaran trabajando para esta causa sin tener mucha conciencia al respecto.
En Conclusión, si bien queda claro que en estricto sentido y rigor histórico, Arpanet y por derecho propio Internet, no nacieron como redes diseñadas para sobrevivir a un ataque Nuclear, ya que su diseño de fragmentado en paquetes, respondió fue a la suma de una serie de casualidades, la búsqueda de estabilidad y la optimización de recursos, el hecho que Paul Baran como uno de los fundadores de la génesis de la red, estuviera trabajando desde RAND Corporation en una red segura de comunicaciones capaz de sobrevivir a un ataque con armas nucleares con claros fines militares y que todo el desarrollo de la red hubiera surgido en el contexto de la guerr fría, pero sobre todo, que el proyecto Arpanet hubiera sido financiado con recursos militares provenientes de la agencia DARPA, evidencia que el “MITO”, no es absurdo desde una perspectiva contextual y representa una parte importante de la problemática del momento histórico y es muy probable que si estos desarrollos no se hubieran dado en el contexto de la Guerra Fría y la amenaza nuclear que la subyace, difícilmente hubieran encontrado la financiación que el proyecto requería.
Enlaces y fuentes que soportan el presente artículo:
[1] Nota publicada por la Universidad Politécnica de Cataluña sobre el Origen de Arpanet e Internet
[2] Artículo de la Enciclopedia Británica sobre Joseph Licklider
[3] Artículo de Wikipedia sobre Bolt, Beranek y Newman BBN
[4] Artículo del Periódico La Nación de Argentina sobre los 50 años de Arpanet
[5] Artículo enciclopédico sobre DARPA en Wikipedia
[6] Artículo de Xataca sobre el origen de Internet y Arpanet
[7] Biografía no oficial de Joseph Licklider publicada como parte de una investigación de la Universidad de Murcia
[8] Biografía de Robert Bob Taylor en Wikipedia
[9] Biografía no oficial de Joseph Licklider publicada como parte de una investigación de la Universidad de Murcia
[10] Análisis del portal especializado MicroSiervos sobre el origen de Internet
[11] Artículo de Xataca sobre el origen de Internet y Arpanet
[12] Enlace el documento publicado por Larry Roberts
[13] Artículo de Muy Historia sobre el origen y contexto de la Guerra Fria
[14] Artículo enciclopédico sobre Paul Baran en Wikipedia
[15] Artículo de Wikipedia sobre el origen de Internet
[16] Enlace al Website de la Universidad UCLA en California
[17] Communication Nets: Stochastic Message Flow and Delay, Leonard Kleinrock, ISBN 0486151115, 9780486151113, 224 páginas
[18] Análisis del portal especializado MicroSiervos sobre el origen de Internet
[19] Artículo de Xataca sobre el origen de Internet y Arpanet
[20] Artículo: Retato del Protocolo IP – Portal especializado ionos.es
Descargo de Responsabilidades: Este artículo corresponde a una revisión y análisis contextual en el contexto de la transformación digital en la sociedad de la información, y está debidamente soportado en fuentes académicas y/o periodísticas confiables y verificadas. Este NO es un artículo de opinión y por tanto la información que contienen no necesariamente representan la postura de Andinalink, LACNIC o la de sus autores o las entidades con las que se encuentren formalmente vinculados, respecto de los temas, personas, entidades u organizaciones mencionadas en el texto.
Suscribirse a:
Entradas (Atom)
Video: Todo lo que necesitas saber sobre los prefijos bogons
Hoy queremos aprender. ¿Sabes qué son los prefijos bogons y por qué representan un riesgo para tu red? En este video analizamos a fondo el...

-
Saludos, Lo primero que debemos de hacer para quitar el stacking entre los switches es desconectar los cables Stack que los unen.... Es buen...
-
 Necesidad Contar con dos routers y una dirección IP en Standby (HSRP), donde ciertas redes origen enrutarlas por el Carrier A y otras redes ...
Necesidad Contar con dos routers y una dirección IP en Standby (HSRP), donde ciertas redes origen enrutarlas por el Carrier A y otras redes ... -
Introduccion: En algunas ocasiones es necesario "bajar" o deshabilitar iptables en nuestro Linux, el procedimiento depende de...