En el mes de IPv6, y justo cuando se cumplen 10 años de recolección de estadísticas de IPv6 por parte de LACNIC, deseamos mostrarte un resumen de los hitos, logros, avances y estadísticas de este protocolo en nuestra región.
Contexto histórico
Hace 10 años -más exactamente en el mes de mayo del 2014- en LACNIC hicimos un pequeño trabajo que ha perdurado hasta estos días y no parece que lo detengamos en un futuro cercano: armamos el colector de estadísticas de IPv6.
¿Colector de estadísticas?
El colector no es más que un script en python3 que se conecta a las estadísticas de google [1], las procesa , limpia y luego almacena en nuestra base de datos. Con estos números desde LACNIC hacemos gran cantidad de cosas, como por ejemplo:
- Página con estadísticas por país https://stats.labs.lacnic.net/IPv6/graph-access.html (por cierto la más visitada en ese portal y utilizada por decenas de personas)
- Creación del ranking de IPv6: https://stats.labs.lacnic.net/IPv6/ipv6ranking.html
- Videos como el bar chart race: https://www.youtube.com/watch?v=l9CKQCa1z0U
- Textos de resumenes anuales como: https://blog.acostasite.com/2019/12/retrospectiva-sobre-el-crecimiento-de.html
¿Qué se mide?
Los números que verán en las gráficas siguientes, representan el porcentaje de penetración de IPv6 en el usuario final, por ejemplo si vemos que dice 30%, significa que de cada 100 personas, 30 ya cuentan con IPv6
Comencemos el paseo
2014. Primero arranquemos con aquellos países que estaban abrazando IPv6 para aquel año. Es decir, países que tenían algo de penetración IPv6 en el 2014 (> 1%), como Perú que ya contaba con un 4,6 % y Ecuador que terminaba dicho año con un poco más de 1%. Ya en esta fechas decíamos “hay que seguir los ejemplo de Ecuador y Perú”.
2015. La carrera por la adopción de IPv6 estaba en pleno apogeo. Este año algunos países comenzaron su carrera en lo que años subsiguientes se verían grandes resultados. Países como Bolivia y Brasil comenzaban sus despliegues de IPv6 y terminaban el año con 3% y 6% respectivamente, dando inicio a su emocionante trayectoria.
2016. En este año Argentina, Guatemala y Trinidad y Tobago se hicieron presentes y lograron finalizar el año con 1,93%, 1% y 11% respectivamente. Es importante mencionar que los países pioneros no detuvieron sus despliegues de IPv6. Por ejemplo Brasil terminaba el año con más de 10% y Ecuador con 18%, siendo el valor más alto para este año. Tomando en cuenta que Brasil tiene una población de 215mm, no era nada malo el 10% :-)
2017. La fiesta de IPv6 seguía creciendo; por ejemplo México alcanzó un 4,5% y Uruguay un envidiable 30%. Este año finaliza con el 10% de latinoamericanos con acceso en IPv6. La fiesta estaba aún entrando en calor.
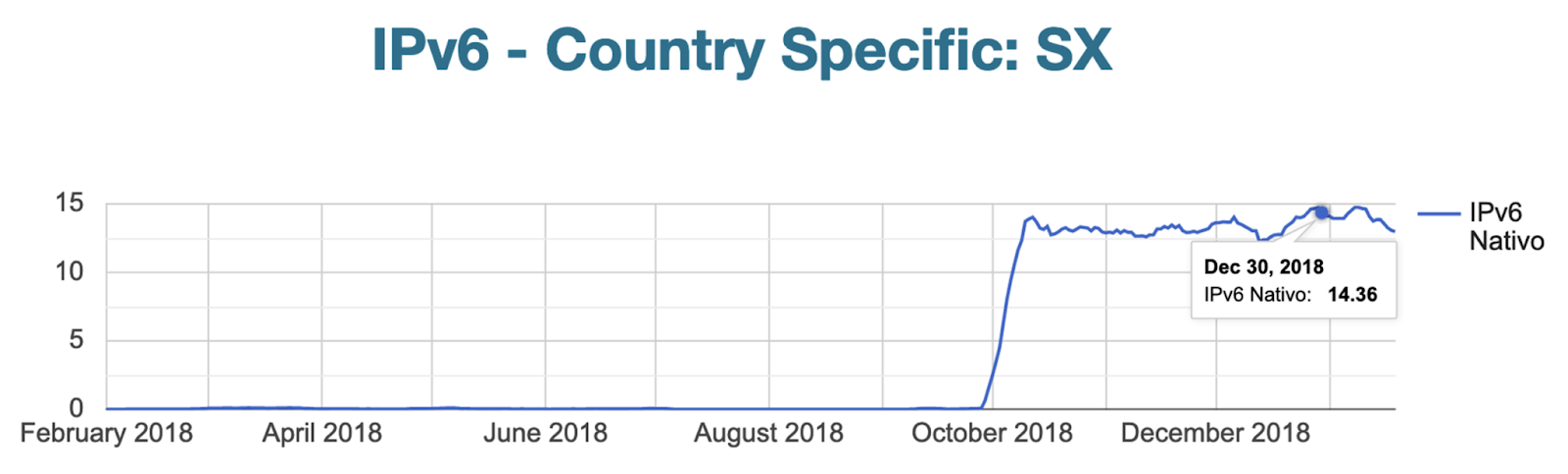
2018 El Caribe es el protagonista anotando tres países más: República Dominicana (1,2%), Sint Marteen (13%) y Belize (1%) dejaron su huella. México tuvo un gran crecimiento moviéndose de 4% a 24%.
2019. El Caribe mostraba su determinación, Guyana Francesa daba un salto asombroso, alcanzando 37% en tiempo récord. Colombia y Paraguay también brillaban con 1,4% y 1,8% respectivamente. Y el resto de la región seguía adelante, con Argentina llegando al 8%, Bolivia al 15%, Brasil al 28%, México al 31%, Perú al 18% ¡el promedio regional del 20%!
2020. La evolución no se detenía; Chile y Surinam rompían barreras, alcanzando 1,2% y 6,8% respectivamente. Nicaragua, Belize, Bolivia y Paraguay mostraban crecimientos notables, con un emocionante avance en IPv6.
2021. Centroamérica se convertía en el epicentro de la acción, El Salvador, Nicaragua y Honduras emergían con 13%, 18% y 6% respectivamente. Guyana continuaba su ascenso, superando el 16%. Y Chile destacaba con un notable crecimiento, ¡1,1% hasta un emocionante 13%!
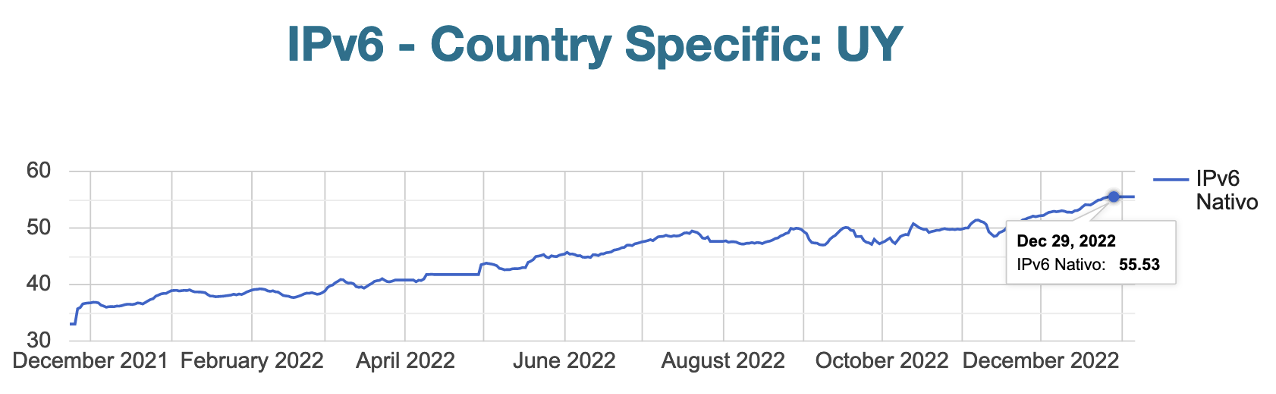
2022 Parecía que la fiebre de IPv6 era contagiosa. Costa Rica y Panamá se sumaban con 5% y 1,1%. Curazao también se unía al movimiento con 1%. Surinam destacaba por un impresionante avance: de un conservador 3% a un impresionante 21%. Uruguay rompía la barrera del 50%, marcando un hito emocionante en la región
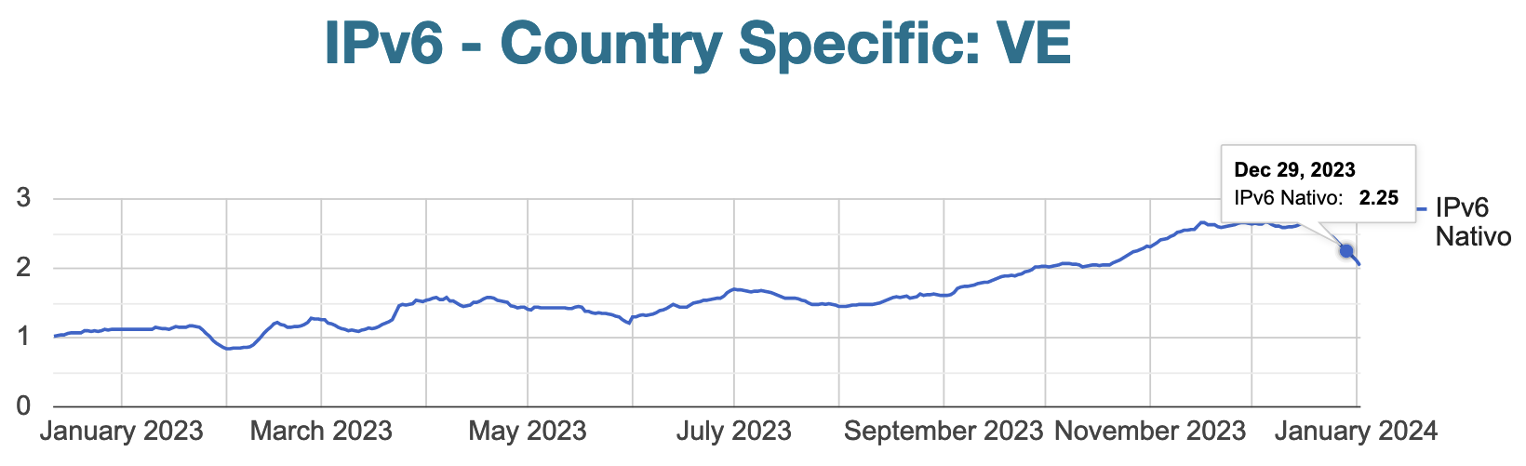
2023 El despliegue a nivel de LAC continúa, con Bonaire, Sint Eustatius y Saba marcando un valiente 1%, mientras que Haití y Venezuela[3] [4] emergen con un prometedor 3% y 2% respectivamente. Para diciembre de este año, un 34% de nuestra región cuenta con IPv6, señalando un avance notable en la adopción del nuevo protocolo.
Conclusiones
La adopción de IPv6 en América Latina y el Caribe comenzó en 2014 con Perú y Ecuador como líderes. A lo largo de los años siguientes, la región experimentó un crecimiento constante, con países como México, Brasil y Bolivia. Para 2022, el impulso continuó, con Costa Rica, Panamá, Argentina y Chile alcanzando cifras destacadas. Con un 34% de la región adoptando IPv6 para fines del 2023, se estableció un hito significativo en el camino hacia un Internet más avanzado y accesible en la región. Uruguay no puede quedar a un lado siendo el único país que supera el 50% de penetración de IPv6 en el usuario final.
Por último, recordemos que alrededor del 30% de la población no se encuentra conectada a Internet, y la manera correcta de llegar a ellos es con IPv6.
Referencias
https://www.google.com/intl/en/ipv6/statistics.html
https://stats.labs.lacnic.net/IPv6/graph-access.html