En el presente post quiero hablar mayormente sobre un documento con poco tiempo en IETF llamado “Ethernet sobre HTTPS”. Debo confesar que su nombre indiscutiblemente me llamó la atención.
Historia
La necesidad de encapsular un protocolo en otro no es nada nuevo. De hecho, esta práctica lleva con nosotros aproximadamente 30 años.
Retrocedamos a la década de los 90. En estos años ocurrió de todo en cuanto a las ideas de encapsular un protocolo en otro. Por ejemplo, IP-IP (IP en IP) apareció cuando Internet estaba en sus primeras etapas de expansión comercial y se buscaban formas de conectar redes privadas sobre la infraestructura de red pública, lo que conocemos hoy en día como Internet.
En esa misma década sin ir muy lejos aparecieron otras tecnologías que aún son muy populares como -el querido- GRE, PPTP, L2TP, e incluso ya a finales de los 90’ y comenzando los 2000, hubo grandes avances con VPNs IPSEC.
Pero no avancemos tanto en el tiempo, vamos a quedarnos un rato más en los 90’. Ya no solo se quería encapsular IPv4 en IPv4, también dieron un paso adelante con IPv6 y apareció el protocolo 41 (IPv6 en IPv4) en 1998.
A partir de aquí el resto es historia. Ya se han realizado cualquier cantidad de “mezclas” de encapsulamientos de protocolos, como IPv4 sobre IPv6, IPv6 sobre UDP sobre IPv4, ethernet sobre IP y un largo etcétera.
Ok, volvamos al draft Ethernet sobre HTTPS
A finales del año 2023, específicamente el día 27 de diciembre dentro del Working Group INTAREA (Internet Area Working Group) llegó un draft con el título Ethernet sobre HTTPS,
¿De qué trata el draft?
El Draft busca definir un protocolo para encapsular tramas ethernet sobre HTTPS, permitiendo una comunicación segura entre clientes y servidores Web internos.
¿Cómo se pretende lograr lo anterior?
Dentro de la sección 1.2 del documento se realiza la siguiente explicación, que podemos resumir en lo siguiente:
El cliente, al especificar una URL interna, reconoce que se debe utilizar Ethernet sobre HTTPS para la comunicación. El navegador del cliente, preconfigurado con la dirección IP y el puerto del Servidor HTTP que actúa como puerta de enlace a la LAN, inicia el protocolo Ethernet sobre HTTPS y envía una solicitud de autenticación al servidor. Una vez autenticado, el cliente envía una solicitud de página web interna encapsulada dentro de una solicitud HTTPS. El servidor desencapsula la trama Ethernet, extrae la solicitud HTTP original y la enruta al servidor web interno. Luego, el servidor encapsula la respuesta del servidor web interno y la envía de vuelta al cliente.
Diagrama de operación
Respuesta al cliente
El draft explica que la respuesta a una solicitud de un cliente es en formato JSON. Un ejemplo sería:
Puntos positivos del draft
Trata de un tema interesante, puede ser novedoso y tener una gran cantidad de implementaciones.
Por el momento es un draft corto y correctamente hace hincapié en el área de seguridad y autenticación.
Dudas que deja el mismo
El problema no queda bien definido, es difícil entender por qué se desea solucionar una situación a nivel HTTP desde Ethernet.
Pareciera que el servidor EoH es similar a un proxy
El área de seguridad a nivel de capa 2 es muy delicada, debería ser al menos mencionada en el draft
Expresan respuestas en json de mac_address y direcciones IP con un ejemplo de IPv4 ☹️
Indiscutiblemente, la explicación del funcionamiento deja muchas dudas
Es muy normal en el mundo de encapsulamiento tener preocupaciones en el área del exceso de payload. Transportar ethernet sobre HTTPS es literalmente cargar todo el modelo TCP/IP en HTTPS
Al punto anterior hay que sumar los posibles problemas de MTU que pueden conllevar este tipo de soluciones.
Ya existen varios trabajos en este sentido, el primero es el draft “Proxying ethernet in HTTP” y un software que hace precisamente lo que promete el draft llamado Softether. Lo anterior sin mencionar “Proxying IP in HTTP” el cual incluso ya es un RFC Standard Track (RFC 9484).
Pronóstico sobre el draft
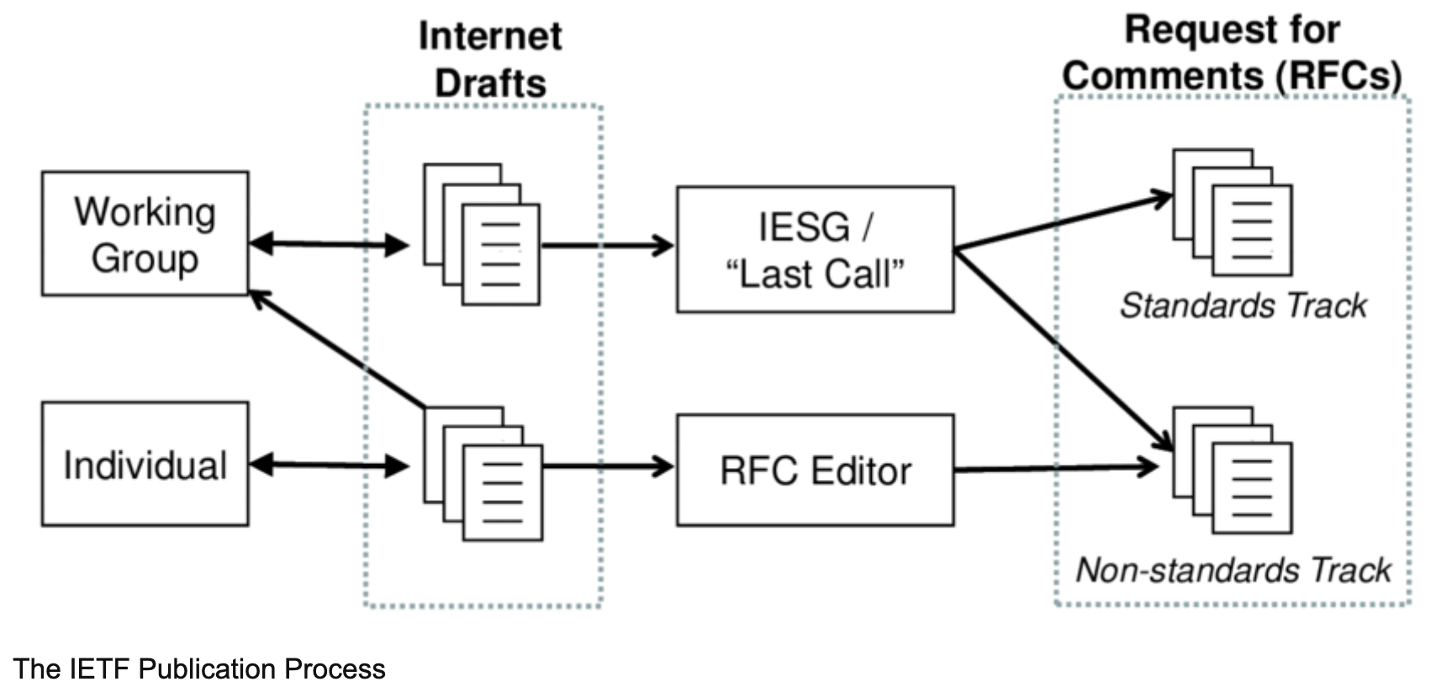
Recordando el funcionamiento de IETF (ver diagrama abajo), donde individuos proponen drafts de manera personal, luego son adoptados por el WG, y más adelante luego de un consenso de la comunidad en varias etapas, el mismo es adoptado como RFC.
The IETF Publication Process
Con la versión actual del mismo, no pareciera que el draft avance mucho. Pienso que quedará lejos del consenso dentro IETF. Hoy en día no se aprecia mayor soporte por parte de la comunidad, sin embargo no quiero descartarlo 100% porque pueden ocurrir cosas que le den un giro al mismo como conseguir nuevos autores, conseguir un “running code”, presentarlo presencialmente y muchas otras cosas.
Conclusiones
Es un draft que propone una idea arriesgada, vamos a llamarla reflexiva, sin un problema claro que resolver. Esto es un claro ejemplo de que no todos los documentos que llegan a IETF son tan elaborados, a veces son solo ideas para medir la temperatura de la comunidad.
¿Qué opinas de este draft? ¿Te ánimas a introducir algún documento a IETF?