Netland, Diciembre 2013
Luego de una reunion casi secreta de una semana en Suiza, los principales fabricantes de hardware y software a nivel mundial tomaron la drástica decisión de no continuar con el desarrollo e implementación de IPv6. Como alternativa decidieron de manera únanime utilizar el mismo protocolo IPv4 y crear un nuevo concepto de sub-IP (IPv4S).
Los detalles técnicos se describieron así: "Vamos a utilizar un bit que se encuentra reservado en la cabecera IPv4 desde su origen (RFC 791), dicho bit al estar encendido los hosts leeran los campos de datos indicando más direcciones IPv4, es decir, es un subgrupo de IPv4". Según el PhD Tniv Frec: "Esto es algo que debió hacerse hace mucho".
A la reunión asistieron en gran cantidad los mejores programadores del mundo los cuales se mostraban muy contentos con esta nueva idea. Ms Avaj, una reconocida en programadora orientada a objetos indicó "Al fin", esto es lo que todos necesitamos, ahora el desarrollo de software será tres veces más rápido.
Con la nueva metodología los fabricantes de hardware y software pueden realizar los ajustes pertinentes de manera más sencilla, rápida y funcional. Para los ISPs y programadores este cambio será transparente debido que ahora cuentan con "SP&P" (Super Plug & Play) donde servidores Web y Mail se autoconfigurarán de manera mágica; Ms Cin indicó que incluso los registros DNS serán realizados sin intervención humana gracias el nuevo registro SeIP (sub enhance IP) donde todos los host hablan con todos los DNSs (full mesh).
Otro participante lllamado Pir, indica que si esto hubiese existido hace 5 años el Internet actual fuera 400 veces más grande y según Mr. Lrep unas 8 veces rápido.
Desde el aspecto social, Ms. Locotorp, menciona que esta nueva versión servirá para disminuir el hambre en el mundo gracias a que es un protocolo pensado en el consumo eléctrico, indica que es 34% más eficiente gracias a su inteligencia incorporada, todo gracias al nuevo bit que nadie había querido usar. Al final de la entrevista dió a atender que es una verguenza que ingenieros de todo el mundo no hubiesen hecho esto años atrás.
Un entrevistado de apellidos Tan Tap que no quiso salir a la luz pública lamenta que IPv6 no hubiese crecido más, indicó que el mal uso del NAT y la gran cantidad de mecanismos de transición le quitaron el impulso a la implementación de IPv6, nuestro reportero indica que Mr Tan Tap siempre tuvo una sonrisa fingida y se rió de todos los que habían implementado IPv6.
Referente a las redes internas, en base a la información de este grandioso bit, dependiendo de si esta completamente encendido o solo un poco se auto-determina si la dirección IP es interna o externa, a su vez reconoce si el host está en una MZ o DMZ, y simultaneamente aplica las políticas de seguridad pertinentes, los administradores de red no tienen necesidad de modificar ninguna política.
Mr. Lufetats indica que apoyándose en IPv4S los firewall serán muy sencillos de implementar, unicamente es necesario colocarlo y voila!.., BCP 38, servicios y otras politicas se autoconfiguran.
Finalmente, dieron a conocer que los conceptos de EGPs e IGPs desaparecerán en unos años. La nueva versión puede hablar inter-AS e intra-AS gracias a sus mecanismos de reconocimiento de rutas, se adapta de Distance Vector a Link State automaticamente según convenga, reconoce saturación de los enlaces, delay, pérdida de paquetes y comprime los datos cuando es necesario. Incluso percibe cuando el CPU del enrutador está sobre cargado y toma acciones correctivas.
Estiman que en solo un año todos los hosts de internet contaran con IPv4S, luego, las capas 4 y 7 del modelo OSI desapareceran porque IPv4S puede a su vez llevar directamente los protocolos de aplicación, con ello se espera que la enseñanza de redes sea trivial.
Saludos,
Att.
Rebif Citpo VI
sábado, 28 de diciembre de 2013
lunes, 15 de julio de 2013
Resumen de FLIP6 en Medellin 2013
Hola todos,
Es un honor para mi escribir en esta ocasión y compartir mis
impresiones de la 11va. edición del FLIP6 (Foro Latino Americano de
IPv6) en la ciudad de Medellin - Colombia durante los días 7 y 9 de
Mayo de 2013.
Cada evento es un desafío. es un reto nuevo; cosas inesperadas pueden
ocurrir, tanto cosas buenas como cosas malas. Lo importante es saber
manejar las situaciones, poderlas llevar y eventualmente poder
superarlas. Tuvimos un gran evento, tanto en el especto técnico,
académico y social.
Antes de entrar de lleno en el resumen del evento, deseo mencionar que
cuando en la vida se presentan situaciones complicadas no hay que
colocar mala cara y mucho menos rendirse, todo lo contrario, hay que
saber canalizar las preocupaciones y angustias en energía y
entusiasmo, esta es la única manera para poder salir adelante.
Recientemente me enteré que Thomas Alva Edison tenía problemas
auditivos, él, en vez de quejarse decía que menos mal, con ello podía
concentrarse más en sus inventos
Resumen del evento:
Antes de cada evento siempre existe un grado de preocupación, las
preocupaciones van desde “ójala no falte ningún speaker”, que el salón
este lleno y que ójala tengamos tiempo para la agenda completa. Me
complace indicar que en esta oportunidad -igual que las anteriores- el
Foro fue un éxito total y hemos salido aún con más fuerza para seguir
trabajando por la promoción de IPv6 en Latinoamérica y Caribe.
El evento tuvo una duración de casi 7 horas dividido en dos días. Por
primera vez compartirmos un espacio de 3 horas con LACSEC, el objetivo
era unir en la agenda aquellas presentaciones con contenido de
seguridad e IPv6. Más adelante les doy los detalles.
Se contó con la asistencia de unas 400 personas en total, que se apreciaba con
el salón lleno en todo momento. Existen muchos puntos a destacar en
esta oportunidad:
- El cumplimiento de los horarios de los ponentes fue excepcional.
- Cantidad de preguntas realizadas
- El evento estuvo acompañado por una gran difusión vía Twitter,
Facebooks y listas de correo.
- Calidad de los expositores
- Temas novedosos en el foro
Como siempre, hay que destacar al comité evaluador de LACTF quienes tuvieron la
importante labor de seleccionar los trabajos presentados en la 11va.
edición del FLIP6. Sin el comité el evento no sería lo mismo. Es
sensacional los estudios y charlas que existen tras bastidores para
seleccionar los temas.
A continuación un breve resumen de cada una de las ponencias:
- Evaluación de la seguridad y diagnóstico de problemas en redes IPv6
- Fernando Gont
Fernando tuvo la oportunidad de abrir FLIP6, con su tradicional estilo
de exposición: sencillo pero con un alto contenido de nivel técnico
expuso una combinación muy llamativa del toolkit de seguridad de IPv6
y problemas existentes en el área. Vale la pena volver a ver.
- El caso de negocio para IPv6 - Mark Townsley, Cisco.
Nuestra presentación Keynote vino dada por el Ing. Mark Townsley,
quien es co-chair del WG Homenet de la IETF y además fellow de Cisco.
Expuso un tema sumamente interesante y necesario: “El caso de negocio
para IPv6”. Su presentación fue dinámica y amena, una vez más quedó
expresado porque es importante la implementación de IPv6. Es una
exposición cuya láminas sin duda muchos de nosotros volveremos a
revisar.
- Conexión a Internet IPv6 de redes corporativas - Álvaro Retana, Cisco.
El Ing Alvaro Retana (Ing distinguido de Cisco) realizó una
presentación de mucho impacto sobre las posibilidades, modalidades y
alternativas de las conexiones a Internet IPv6 en redes corporativas.
Muy interesante, gracias por compartir esta información. Esperemos que
crezca significativamente el sector corporativo en su implementación
de IPv6 en los próximos años.
- Mejores prácticas en nubes públicas para garantizar su seguridad,
respaldo y alta disponibilidad - Efraín Soler, CEO de O4IT.
Efarin Soler realizó una exposición sobre la plataforma,
tecnología implementada, marco de seguridad y la sencilla interfaz Web
que O4IT tiene para ofrecer. Sin duda alguna muchos de los asistentes
apredimos de este prestigioso sponsor.
- Actualización sobre IPv6 en redes de Gobierno - Jordi Palet, Consulintel.
Jordi, con su acostumbrado estilo de enseñar y transmitir
información brindó un rápido repaso pero muy importante sobre los
avances en la implementación en algunos países y gobiernos. Mil
gracias por compartir esta información con nosotros. Te esperamos para
que compartas nuevos avances.
- Casos de éxito en implementaciones de IPv6. Evandro Varonil,
Guillermo Cicileo.
Los Ingenieros Evandro Varonil y Guillermo Cicileo
expusieron muy vividamente sus experiencias implementando IPv6 en sus
organizaciones. Desde FLIP6 estamos muy agradecidos por compartir este
contenido debido a que el mismo ayuda a los interesados que aún no lo
han hecho a prever algunas situaciones.
- Mobile IPv6 Test Bed: una implementación actualizada - Sebastián
Tobar y Cristian Pérez Monte, Grupo UTN GridTICS (AR)
Sebastian Tobas y Cristian Perez Monte realizaron una
llamativa exposición sobre IPv6 y movilidad. La ponencia fue muy
ilustrativa y decarácterr novedoso. Ojalá tengamos la oportunidad de
conocer los avances en los próximos meses y/o años.
- Análisis de las técnicas de transición para un mundo sin IPv4 -
Rodrigo Regis dos Santos, NIC.br.
El Ing. Rodrigo Regis dos Santos realizó una exposición muy
completa cubriendo la mayoría los métodos de transición puntualizando
muy bien las ventajas y desventajas de cada uno de ellos.
¡Muchas gracias por una presentación tan agradable!
- Consideraciones operativas sobre planificación y despliegue de IPv6
- Álvaro Retana, Cisco
Alvaro Retana le tocó aperturar el estreno en el espacio
compartido de LACSEC/FLIP6. Una vez más realizó una fantástica
presentación sobre las consideraciones operativas durante el
despliegue de IPv6, hizo mucho énfasis en la planificación. Fue
probablemente unas de las presentaciones con mayor participación de
los asistentes, Hubo al menos una hora de preguntas, respuestas y
comentarios luego de finalizar la ponencia. Ojala podamos repetir esta
experiencia.
- Avances recientes en seguridad de IPv6 - Fernando Gont, SI6 Networks.
Fernando Gont, por segunda vez durante FLIP6 de 2013 conversó sobre
IPv6 y la seguridad, dejando como moraleja que las implementaciones de
este protocolo a su vez deben venir acompañado de políticas de
seguridad, existen problemas que son similares a IPv4 y otros que son
únicamente de IPv6. Ojala contemos con Fernando Gont en futuras
reuniones de FLIP6.
Conclusión:
Para concluir, tuvimos otra edición de FLIP6 inolvidable, una vez más
intentamos empujar difundir már IPv6 en los asistentes. Después de
cada evento nos despedimos con la intención de que regresen a sus
casas y oficinas con el objetivo de implementar IPv6. Una vez escuché:
“IPv6 is not optional anymore, it’s a must.” (IPv6 ya no es opcional,
es obligatorio)
Para finalizar una pequeña cita para que siga la evolución informática
y con ello IPv6:
“El verdadero progreso es el que pone la tecnología al alcance de todos.”
— Henry Ford
Att.
Alejandro Acosta
Chair LACTF/FLIP6 2013
http://aaaa.acostasite.com
Twitter: @lactf
Es un honor para mi escribir en esta ocasión y compartir mis
impresiones de la 11va. edición del FLIP6 (Foro Latino Americano de
IPv6) en la ciudad de Medellin - Colombia durante los días 7 y 9 de
Mayo de 2013.
Cada evento es un desafío. es un reto nuevo; cosas inesperadas pueden
ocurrir, tanto cosas buenas como cosas malas. Lo importante es saber
manejar las situaciones, poderlas llevar y eventualmente poder
superarlas. Tuvimos un gran evento, tanto en el especto técnico,
académico y social.
Antes de entrar de lleno en el resumen del evento, deseo mencionar que
cuando en la vida se presentan situaciones complicadas no hay que
colocar mala cara y mucho menos rendirse, todo lo contrario, hay que
saber canalizar las preocupaciones y angustias en energía y
entusiasmo, esta es la única manera para poder salir adelante.
Recientemente me enteré que Thomas Alva Edison tenía problemas
auditivos, él, en vez de quejarse decía que menos mal, con ello podía
concentrarse más en sus inventos
Resumen del evento:
Antes de cada evento siempre existe un grado de preocupación, las
preocupaciones van desde “ójala no falte ningún speaker”, que el salón
este lleno y que ójala tengamos tiempo para la agenda completa. Me
complace indicar que en esta oportunidad -igual que las anteriores- el
Foro fue un éxito total y hemos salido aún con más fuerza para seguir
trabajando por la promoción de IPv6 en Latinoamérica y Caribe.
El evento tuvo una duración de casi 7 horas dividido en dos días. Por
primera vez compartirmos un espacio de 3 horas con LACSEC, el objetivo
era unir en la agenda aquellas presentaciones con contenido de
seguridad e IPv6. Más adelante les doy los detalles.
Se contó con la asistencia de unas 400 personas en total, que se apreciaba con
el salón lleno en todo momento. Existen muchos puntos a destacar en
esta oportunidad:
- El cumplimiento de los horarios de los ponentes fue excepcional.
- Cantidad de preguntas realizadas
- El evento estuvo acompañado por una gran difusión vía Twitter,
Facebooks y listas de correo.
- Calidad de los expositores
- Temas novedosos en el foro
Como siempre, hay que destacar al comité evaluador de LACTF quienes tuvieron la
importante labor de seleccionar los trabajos presentados en la 11va.
edición del FLIP6. Sin el comité el evento no sería lo mismo. Es
sensacional los estudios y charlas que existen tras bastidores para
seleccionar los temas.
A continuación un breve resumen de cada una de las ponencias:
- Evaluación de la seguridad y diagnóstico de problemas en redes IPv6
- Fernando Gont
Fernando tuvo la oportunidad de abrir FLIP6, con su tradicional estilo
de exposición: sencillo pero con un alto contenido de nivel técnico
expuso una combinación muy llamativa del toolkit de seguridad de IPv6
y problemas existentes en el área. Vale la pena volver a ver.
- El caso de negocio para IPv6 - Mark Townsley, Cisco.
Nuestra presentación Keynote vino dada por el Ing. Mark Townsley,
quien es co-chair del WG Homenet de la IETF y además fellow de Cisco.
Expuso un tema sumamente interesante y necesario: “El caso de negocio
para IPv6”. Su presentación fue dinámica y amena, una vez más quedó
expresado porque es importante la implementación de IPv6. Es una
exposición cuya láminas sin duda muchos de nosotros volveremos a
revisar.
- Conexión a Internet IPv6 de redes corporativas - Álvaro Retana, Cisco.
El Ing Alvaro Retana (Ing distinguido de Cisco) realizó una
presentación de mucho impacto sobre las posibilidades, modalidades y
alternativas de las conexiones a Internet IPv6 en redes corporativas.
Muy interesante, gracias por compartir esta información. Esperemos que
crezca significativamente el sector corporativo en su implementación
de IPv6 en los próximos años.
- Mejores prácticas en nubes públicas para garantizar su seguridad,
respaldo y alta disponibilidad - Efraín Soler, CEO de O4IT.
Efarin Soler realizó una exposición sobre la plataforma,
tecnología implementada, marco de seguridad y la sencilla interfaz Web
que O4IT tiene para ofrecer. Sin duda alguna muchos de los asistentes
apredimos de este prestigioso sponsor.
- Actualización sobre IPv6 en redes de Gobierno - Jordi Palet, Consulintel.
Jordi, con su acostumbrado estilo de enseñar y transmitir
información brindó un rápido repaso pero muy importante sobre los
avances en la implementación en algunos países y gobiernos. Mil
gracias por compartir esta información con nosotros. Te esperamos para
que compartas nuevos avances.
- Casos de éxito en implementaciones de IPv6. Evandro Varonil,
Guillermo Cicileo.
Los Ingenieros Evandro Varonil y Guillermo Cicileo
expusieron muy vividamente sus experiencias implementando IPv6 en sus
organizaciones. Desde FLIP6 estamos muy agradecidos por compartir este
contenido debido a que el mismo ayuda a los interesados que aún no lo
han hecho a prever algunas situaciones.
- Mobile IPv6 Test Bed: una implementación actualizada - Sebastián
Tobar y Cristian Pérez Monte, Grupo UTN GridTICS (AR)
Sebastian Tobas y Cristian Perez Monte realizaron una
llamativa exposición sobre IPv6 y movilidad. La ponencia fue muy
ilustrativa y decarácterr novedoso. Ojalá tengamos la oportunidad de
conocer los avances en los próximos meses y/o años.
- Análisis de las técnicas de transición para un mundo sin IPv4 -
Rodrigo Regis dos Santos, NIC.br.
El Ing. Rodrigo Regis dos Santos realizó una exposición muy
completa cubriendo la mayoría los métodos de transición puntualizando
muy bien las ventajas y desventajas de cada uno de ellos.
¡Muchas gracias por una presentación tan agradable!
- Consideraciones operativas sobre planificación y despliegue de IPv6
- Álvaro Retana, Cisco
Alvaro Retana le tocó aperturar el estreno en el espacio
compartido de LACSEC/FLIP6. Una vez más realizó una fantástica
presentación sobre las consideraciones operativas durante el
despliegue de IPv6, hizo mucho énfasis en la planificación. Fue
probablemente unas de las presentaciones con mayor participación de
los asistentes, Hubo al menos una hora de preguntas, respuestas y
comentarios luego de finalizar la ponencia. Ojala podamos repetir esta
experiencia.
- Avances recientes en seguridad de IPv6 - Fernando Gont, SI6 Networks.
Fernando Gont, por segunda vez durante FLIP6 de 2013 conversó sobre
IPv6 y la seguridad, dejando como moraleja que las implementaciones de
este protocolo a su vez deben venir acompañado de políticas de
seguridad, existen problemas que son similares a IPv4 y otros que son
únicamente de IPv6. Ojala contemos con Fernando Gont en futuras
reuniones de FLIP6.
Conclusión:
Para concluir, tuvimos otra edición de FLIP6 inolvidable, una vez más
intentamos empujar difundir már IPv6 en los asistentes. Después de
cada evento nos despedimos con la intención de que regresen a sus
casas y oficinas con el objetivo de implementar IPv6. Una vez escuché:
“IPv6 is not optional anymore, it’s a must.” (IPv6 ya no es opcional,
es obligatorio)
Para finalizar una pequeña cita para que siga la evolución informática
y con ello IPv6:
“El verdadero progreso es el que pone la tecnología al alcance de todos.”
— Henry Ford
Att.
Alejandro Acosta
Chair LACTF/FLIP6 2013
http://aaaa.acostasite.com
Twitter: @lactf
jueves, 30 de mayo de 2013




domingo, 14 de abril de 2013

viernes, 22 de febrero de 2013
Publicar prefijos IPv4 sobre una sesión eBGP IPv6
Situación:
Deseo publicar redes/prefijos IPv4 sobre una sesión eBGP en IPv6
Historia:
A pesar de no ser común este caso pueden ocurrir en algunas situaciones.
Solución:
Afortunadamente BGP soporta llevar información de enrutamiento de distintos protocolos (pe. IPv6/IPv4). Por ello es posible intercambiar información IPv4 dentro de una sesión eBGP IPv6.
Configuración:
En un escenario con R1 conectado a R2 back-to-back la configuración queda de la siguiente manera (deseo que el prefijo anunciado por R2 lo aprenda R1).
R1:
!
interface Ethernet0
ip address 22.22.22.21 255.255.255.252
ipv6 address 2001:DB8::1/64
!
router bgp 1
bgp log-neighbor-changes
neighbor 2001:DB8::2 remote-as 2
neighbor 2001:DB8::2 ebgp-multihop 3
!
address-family ipv4
neighbor 2001:DB8::2 activate
neighbor 2001:DB8::2 route-map IPv4 in
no auto-summary
no synchronization
exit-address-family
!
route-map IPv4 permit 5
set ip next-hop 22.22.22.22
!
R2:
!
interface Ethernet0
ip address 22.22.22.22 255.255.255.252
half-duplex
ipv6 address 2001:DB8::2/64
!
router bgp 2
bgp log-neighbor-changes
neighbor 2001:DB8::1 remote-as 1
neighbor 2001:DB8::1 ebgp-multihop 3
!
address-family ipv4
neighbor 2001:DB8::1 activate
no auto-summary
no synchronization
network 2.2.2.0 mask 255.255.255.0
exit-address-family
!
"El truco":
* La sesión eBGP debe ser obligatoriamente multihop, sino, R1 no aprenderá la ruta. Reconozco que no entiendo 100% porque ocurre sin embargo en base a las lecturas el router se queja que el next-hop y el IP de establecimiento son diferentes y no en la misma subred (lógico, uno es IPv6 y el otro IPv4!).
* En R1 quien aprende la ruta debe tener un route-map aplicado cuando aprende las mismas (in) forzando el next-hop con la dirección IPv4 de R2
Mas información:
- http://www.cisco.com/en/US/docs/ios-xml/ios/ipv6/configuration/15-2mt/ip6-mptcl-bgp.html#GUID-06407EF3-4FAD-4519-A2A9-6CC6037288C0
- Publicando prefijos IPv6 sobre sesiones BGP IPv4 en Cisco
Espero sea útil!
Deseo publicar redes/prefijos IPv4 sobre una sesión eBGP en IPv6
Historia:
A pesar de no ser común este caso pueden ocurrir en algunas situaciones.
Solución:
Afortunadamente BGP soporta llevar información de enrutamiento de distintos protocolos (pe. IPv6/IPv4). Por ello es posible intercambiar información IPv4 dentro de una sesión eBGP IPv6.
Configuración:
En un escenario con R1 conectado a R2 back-to-back la configuración queda de la siguiente manera (deseo que el prefijo anunciado por R2 lo aprenda R1).
R1:
!
interface Ethernet0
ip address 22.22.22.21 255.255.255.252
ipv6 address 2001:DB8::1/64
!
router bgp 1
bgp log-neighbor-changes
neighbor 2001:DB8::2 remote-as 2
neighbor 2001:DB8::2 ebgp-multihop 3
!
address-family ipv4
neighbor 2001:DB8::2 activate
neighbor 2001:DB8::2 route-map IPv4 in
no auto-summary
no synchronization
exit-address-family
!
route-map IPv4 permit 5
set ip next-hop 22.22.22.22
!
R2:
!
interface Ethernet0
ip address 22.22.22.22 255.255.255.252
half-duplex
ipv6 address 2001:DB8::2/64
!
router bgp 2
bgp log-neighbor-changes
neighbor 2001:DB8::1 remote-as 1
neighbor 2001:DB8::1 ebgp-multihop 3
!
address-family ipv4
neighbor 2001:DB8::1 activate
no auto-summary
no synchronization
network 2.2.2.0 mask 255.255.255.0
exit-address-family
!
"El truco":
* La sesión eBGP debe ser obligatoriamente multihop, sino, R1 no aprenderá la ruta. Reconozco que no entiendo 100% porque ocurre sin embargo en base a las lecturas el router se queja que el next-hop y el IP de establecimiento son diferentes y no en la misma subred (lógico, uno es IPv6 y el otro IPv4!).
* En R1 quien aprende la ruta debe tener un route-map aplicado cuando aprende las mismas (in) forzando el next-hop con la dirección IPv4 de R2
Mas información:
- http://www.cisco.com/en/US/docs/ios-xml/ios/ipv6/configuration/15-2mt/ip6-mptcl-bgp.html#GUID-06407EF3-4FAD-4519-A2A9-6CC6037288C0
- Publicando prefijos IPv6 sobre sesiones BGP IPv4 en Cisco
Espero sea útil!
domingo, 17 de febrero de 2013
Publicando prefijos IPv6 sobre sesiones BGP IPv4 en Cisco
Situación:
Deseo publicar redes/prefijos IPv6 sobre una sesión eBGP en IPv4
Historia:
A pesar de no ser común este caso pueden ocurrir en algunas situaciones. En esta oportunidad, tengo un router Cisco con soporte IPv6 (routing) pero su configuración BGP no permite definir neighbors IPv6
Error:
Mensaje que quizás estas recibiendo y el mismo te trajo a esta página :)
*Mar 1 02:05:00.663: BGP: 1.1.1.1 Advertised Nexthop ::FFFF:1.1.1.1: Non-local or Nexthop and peer Not on same interface
*Mar 1 02:05:00.663: BGP(1): 1.1.1.1 rcv UPDATE w/ attr: nexthop ::FFFF:1.1.1.1, origin i, metric 0, originator 0.0.0.0, path 1, community , extended community
*Mar 1 02:05:00.667: BGP(1): 1.1.1.1 rcv UPDATE about 2001:db8::/32 -- DENIED due to:
*Mar 1 02:05:00.667: BGP(0): Revise route installing 1 of 1 route for 10.0.0.0/24 -> 1.1.1.1 to main IP table
*Mar 1 02:05:00.771: BGP(0): 1.1.1.1 computing updates, afi 0, neighbor version 0, table version 25, starting at 0.0.0.0
Solución:
Afortunadamente BGP soporta llevar información de enrutamiento de distintos protocolos (pe. IPv6). Por ello es posible intercambiar información IPv6 dentro de una sesión eBGP IPv4.
Configuración:
En un escenario con R1 conectado a R2 back-to-back la configuración queda de la siguiente manera (deseo que el prefijo anunciado por R1 lo aprenda R2).
R1:
!
interface Ethernet1/0
ip address 1.1.1.2 255.255.255.252
full-duplex
ipv6 address 2001:db8::1/64
ipv6 enable
!
router bgp 1
no synchronization
bgp router-id 1.1.1.1
bgp log-neighbor-changes
neighbor 1.1.1.2 remote-as 2
neighbor 1.1.1.2 ebgp-multihop 2
no auto-summary
!
address-family ipv6
neighbor 1.1.1.2 activate
network 2001:db8::/32
no synchronization
redistribute static
exit-address-family
!
ipv6 route 2001:db8::/32 Null0
R2:
!
interface Ethernet1/0
ip address 1.1.1.2 255.255.255.252
full-duplex
ipv6 address 2001:db8::2/64
ipv6 enable
!
router bgp 2
no synchronization
bgp router-id 1.1.1.2
bgp log-neighbor-changes
neighbor 1.1.1.1 remote-as 1
neighbor 1.1.1.1 ebgp-multihop 2
no auto-summary
!
address-family ipv6
neighbor 1.1.1.1 activate
neighbor 1.1.1.1 route-map IPv6-NextHop in
exit-address-family
!
route-map IPv6-NextHop permit 10
set ipv6 next-hop 2001:db8::1
!
"El truco":
* La sesión eBGP debe ser obligatoriamente multihop, sino, R2 no aprenderá la ruta (el mismo error que se ve arriba). Reconozco que no entiendo 100% porque ocurre sin embargo en base a las lecturas el router se queja que el next-hop y el IP de establecimiento son diferentes y no en la misma subred (lógico, uno es IPv6 y el otro IPv4!).
* En R2 quien aprende la ruta debe haber un route-map aplicado cuando aprende las rutas (in) forzando el next-hop con la dirección IPv6 de R1
Después de aplicar ebgp-multihop (todo funciona):
*Mar 1 02:01:42.539: BGP(1): 1.1.1.1 rcvd UPDATE w/ attr: nexthop ::FFFF:1.1.1.1, origin i, metric 0, path 1
*Mar 1 02:01:42.539: BGP(1): 1.1.1.1 rcvd 2800:26::/32
*Mar 1 02:01:42.543: BGP(0): Revise route installing 1 of 1 route for 10.0.0.0/24 -> 1.1.1.1 to main IP table
*Mar 1 02:01:42.543: BGP(1): Revise route installing 2001:db8::/32 -> 2001:db8::1 (::) to main IPv6 table
Mas información:
- https://supportforums.cisco.com/docs/DOC-21110
- http://ieoc.com/forums/p/15154/130174.aspx
- http://ieoc.com/forums/p/15154/130174.aspx
Espero sea útil!
Deseo publicar redes/prefijos IPv6 sobre una sesión eBGP en IPv4
Historia:
A pesar de no ser común este caso pueden ocurrir en algunas situaciones. En esta oportunidad, tengo un router Cisco con soporte IPv6 (routing) pero su configuración BGP no permite definir neighbors IPv6
Error:
Mensaje que quizás estas recibiendo y el mismo te trajo a esta página :)
*Mar 1 02:05:00.663: BGP: 1.1.1.1 Advertised Nexthop ::FFFF:1.1.1.1: Non-local or Nexthop and peer Not on same interface
*Mar 1 02:05:00.663: BGP(1): 1.1.1.1 rcv UPDATE w/ attr: nexthop ::FFFF:1.1.1.1, origin i, metric 0, originator 0.0.0.0, path 1, community , extended community
*Mar 1 02:05:00.667: BGP(1): 1.1.1.1 rcv UPDATE about 2001:db8::/32 -- DENIED due to:
*Mar 1 02:05:00.667: BGP(0): Revise route installing 1 of 1 route for 10.0.0.0/24 -> 1.1.1.1 to main IP table
*Mar 1 02:05:00.771: BGP(0): 1.1.1.1 computing updates, afi 0, neighbor version 0, table version 25, starting at 0.0.0.0
Solución:
Afortunadamente BGP soporta llevar información de enrutamiento de distintos protocolos (pe. IPv6). Por ello es posible intercambiar información IPv6 dentro de una sesión eBGP IPv4.
Configuración:
En un escenario con R1 conectado a R2 back-to-back la configuración queda de la siguiente manera (deseo que el prefijo anunciado por R1 lo aprenda R2).
R1:
!
interface Ethernet1/0
ip address 1.1.1.2 255.255.255.252
full-duplex
ipv6 address 2001:db8::1/64
ipv6 enable
!
router bgp 1
no synchronization
bgp router-id 1.1.1.1
bgp log-neighbor-changes
neighbor 1.1.1.2 remote-as 2
neighbor 1.1.1.2 ebgp-multihop 2
no auto-summary
!
address-family ipv6
neighbor 1.1.1.2 activate
network 2001:db8::/32
no synchronization
redistribute static
exit-address-family
!
ipv6 route 2001:db8::/32 Null0
R2:
!
interface Ethernet1/0
ip address 1.1.1.2 255.255.255.252
full-duplex
ipv6 address 2001:db8::2/64
ipv6 enable
!
router bgp 2
no synchronization
bgp router-id 1.1.1.2
bgp log-neighbor-changes
neighbor 1.1.1.1 remote-as 1
neighbor 1.1.1.1 ebgp-multihop 2
no auto-summary
!
address-family ipv6
neighbor 1.1.1.1 activate
neighbor 1.1.1.1 route-map IPv6-NextHop in
exit-address-family
!
route-map IPv6-NextHop permit 10
set ipv6 next-hop 2001:db8::1
!
"El truco":
* La sesión eBGP debe ser obligatoriamente multihop, sino, R2 no aprenderá la ruta (el mismo error que se ve arriba). Reconozco que no entiendo 100% porque ocurre sin embargo en base a las lecturas el router se queja que el next-hop y el IP de establecimiento son diferentes y no en la misma subred (lógico, uno es IPv6 y el otro IPv4!).
* En R2 quien aprende la ruta debe haber un route-map aplicado cuando aprende las rutas (in) forzando el next-hop con la dirección IPv6 de R1
Después de aplicar ebgp-multihop (todo funciona):
*Mar 1 02:01:42.539: BGP(1): 1.1.1.1 rcvd UPDATE w/ attr: nexthop ::FFFF:1.1.1.1, origin i, metric 0, path 1
*Mar 1 02:01:42.539: BGP(1): 1.1.1.1 rcvd 2800:26::/32
*Mar 1 02:01:42.543: BGP(0): Revise route installing 1 of 1 route for 10.0.0.0/24 -> 1.1.1.1 to main IP table
*Mar 1 02:01:42.543: BGP(1): Revise route installing 2001:db8::/32 -> 2001:db8::1 (::) to main IPv6 table
Mas información:
- https://supportforums.cisco.com/docs/DOC-21110
- http://ieoc.com/forums/p/15154/130174.aspx
- http://ieoc.com/forums/p/15154/130174.aspx
Espero sea útil!
lunes, 21 de enero de 2013
Convertir un Access point Cisco Aironet 1242 modo Lightweigth a Access point modo Autónomo/Stand Alone
Situacion:
La mayoría de estos equipos Cisco Aironet vienen con la IOS (Internetwork
Operating System) para que funcione en modo Lightweigth y por más que trates de
configurarlos por cualquier vía no lo vas a poder hacer si no tienes un WLC
(Wireless Lan Controller) los cuales son algo costosos.
El problema de los Access Point (AP) en modo Lighweigth es que toman la
configuración del WLC (Wireless Lan Controller) que esté presente en la red, por
esto estos AP se les conoce como zero touch debido a que no hace falta
realizarle casi ninguna configuración. En
resumen si no tenemos un WLC no podremos configurar el AP vía web ni vía
consola.
Si ingresas vía consola (Hiperterminal u otro) te va a pedir la contraseña de modo privilegiado la cual por defecto es “Cisco”
después de eso cuando intentes pasar a modo global ejecutando el comando
“configure terminal” como en el cualquier dispositivo CISCO te aparecerá el siguiente
mensaje ”command not found”, yo también me preocupé en ese momento pensé que el
dispositivo tenía algún tipo de problema, ejecuté cualquier cantidad de comandos existentes para pasar a modo de
configuración pero nada.
Intenté conectarme vía web, por defecto el AP viene con la
dirección 10.0.0.1 simplemente lo conecte mediante su puerto Ethernet a mi computadora a la cual le asigne la
dirección 10.0.0.2, probé la conectividad con el comando ping entre ellos y
todo estaba perfecto pero en el momento de intentaba ingresar vía web (mediante
un explorador de internet e.g Internet Explorer ,Mozilla Firefox ,colocaba la
dirección 10.0.0.1) no me dejaba ,simplemente es que en el modo Lightweight no
tenemos acceso al AP vía web.
La solución:
La solución es cambiarle la IOS al AP para que este funcione
en modo Autónomo o Stand Alone en vez de Lightweight y así poder configurar el AP normalmente
ya sea vía Web o mediante consola.
Procedimiento:
Los siguientes son los pasos para revertir un AP que esta en
modo LWAPP a modo Autónomo cargando un Cisco IOS utilizando un servidor TFTP.
1.- En nuestra PC cargamos un servidor TFTP en esta misma
maquina configuraremos el AP.
2.- El PC se comportara como el servidor TFTP le asignaremos
por ejemplo la dirección 10.0.0.2 (acordémonos que el AP por defecto tiene la
10.0.0.1)al mismo tiempo nos conectamos mediante el cable de consola al AP
mediante la aplicación Hiperterminal.
3.- Después que conseguimos la nueva IOS (c1240-k9w7-tar.default)
la copiamos a la carpeta donde guarda el
servidor TFTP los archivos por defecto. (debemos que asegurarnos de que tenemos
la nueva IOS en el PC que esta como
servidor TFTP)
4.- El siguiente paso simplemente es conectar el AP a nuestro PC
(servidor TFTP) mediante un cable utp.
5.- Desconecte el AP de la corriente eléctrica.
6.- Conectamos el AP a la corriente eléctrica al mismo tiempo
que mantenemos presionado el botón MODE
en el AP.
7.- Esto lo hacemos alrededor de 20 a 30 segundos el LED de AP
se coloca de color lila, como tenemos abierta la aplicación Hiperterminal en ella nos debería aparecer el
siguiente mensaje “button is pressed ,wait for button to be released…”
8.- En este momento la nueva IOS se esta copiando desde el servidor
TFTP a la flash del AP, simplemente debemos esperar a que se termine de copiar.
9.- Automáticamente la nueva IOS reemplazara a la anterior.
10.- Lo único que nos queda es por fin empezar a configurar
nuestro AP ya sea vía consola o vía web.
Nota: para
conseguir la IOS que necesitamos solo debemos colocar en google lo siguiente “ c1240-k9w7-tar.default shared “ abrimos
el primer resultado que nos arroje, y la descargamos.
Nota: para poder
ingresar vía web al AP este necesita tener configurado una dirección ip, además
de un usuario con nivel 15 de privilegio, lo creamos de la siguiente manera:
AP (config)
username “nombre usuario” privilege 15 password “password”.
Nota: para
descargar el servidor TFTP simplemente hazlo desde esta página
http://www.winagents.com/en/downloads/download-tftp-server.php.
1.-Le colocamos
nombre al AP
Router (config)hostname AP
2.-Configuramos un
SSID al AP podemos tener varios SSID.(por ejemplo le colocamos WIRELESS)
AP (config)dot11 ssid WIRELESS
AP (config-ssid)authentication open
AP (config-ssid)infraestructura ssid
AP (config-ssid) guest mode
(el AP divulgara el SSID para
que los clientes lo puedan ver)
AP (config-ssid) authentication key management wpa versión
2(opcional le configuramos el protocolo WPA versión 2 para la forma en que
administrara las claves)
AP (config-ssid)wpa-psk
ascii “clave”(definimos la contraseña para que los clientes puedan
conectarse al AP)
El AP posee 2 interfaces dot11radio0 (2.4 GHz) y dot11radio1
( 5 GHz)
3.-Asociamos el
SSID a la interface a cual queremos que los clientes se conecten.
Interface
Dot11radio0
AP (config-if)
ssid WIRELESS
AP (config-if)
station-role root (por defecto viene así)
AP (config-if) encryption mode ciphers aes-ccm (opcional,
definimos AES como el algoritmo de encriptamiento)
AP (config-if) no shutdown (levantamos la interface)
4.-Le asignamos
una ip al AP estáticamente para administración (por ejemplo 192.168.1.1) o si
existe un servidor DHCP simplemente dejamos que el AP reciba un IP del mismo.
(config)
interface BVI 1
(config-if)
ip address 192.168.1.1 255.255.255.0
(config-if) no shutdown
Procedimiento realizado por: @AlejandroFerrer
lunes, 14 de enero de 2013
miércoles, 2 de enero de 2013
DNS64 y NAT64 paso a paso con explicación
Introducción:
DNS64 y NAT64 son dos tecnología diferentes que comunmente trabajan en conjunto.
DNS64 y NAT64 es ideal para colocar en el borde una red donde unicamente existan host con IPv6, algo cada día es más común sobre todo en el mundo de redes celulares y se gran cantidad de sensores.
En Internet hay mucha información sobre como configurar NAT64 y DNS64, la mayoría dice que muy fácil, otros lo colocan más complicado. En lo personal no conseguí ninguna que explicara paso a paso como hacerlo y adicionalmente que explicara la topología de red donde se estaba configurando.
En este post comienzo instalando DNS64 y luego procedemos con NAT64. Se puede instalar en cualquier orden.
Que se necesita antes de comenzar:
- Una subred IPv6 libre (una /96 esta bien) para realizar el mapeo DNS entre IPv4 e IPv6. Esta misma subred la utilizaremos dentro de Tayga para el NAT64
- Logicamente conectividad IPv6 entre los clientes y el servidor DNS64 y NAT64 (no se requiere IPv4)
Topología:
a) Servidor realizando. Solo tiene una interfaz (eth1)
IPv6: 2001:db8:1:1::/64 (eth1).
IPv4: 192.168.124.107
b) IP de un cliente (eth2):
2001:db8:1:1::2/64
c) Subredes IPv6:
Red que "retorna" el DNS64 2001:db8:1:ffff::/96
Pool de NAT en el NAT64: 2001:db8:1:ffff::/96
(si, son el mismo bloque)
d) Interfaz dns64:
192.168.124.107/32
2001:db8:1::1/128
(correcto!, la IPv6 e IPv4 de eth1 se solapan con interfaz dns64)
Procedimiento de DNS64.
Paso 1:
Instalar BIND9:
#aptitude install bind9
Paso 2:
Configurar /etc/bind/named.conf.options:
a) Asegurar que BIND escuche en IPv6 (recordemos que los clientes van a estar en IPv6)
listen-on-v6 { any; };
b) Permitir consultas desde cualquier IP. Si estas utilizando un servidor público o en producción favor restringir las consultas a tus clientes
allow-query { any; };
c) Realizar el DNS64 con la siguiente directiva.
dns64 2001:db8:1:ffff::/96 {
clients {
any; };
};
La configuración del punto "c" lo que indica es que aquellas consultas DNS de aquellos registros que SOLO tienen tienen registro A (no tienen registro AAAA) serán entregadas a los clientes añadiendo 2001:db8::1:ffff::/96
d) Reiniciar bind9
#/etc.init.d/bind9 restart
Probar DNS64:
a) En un PC cliente colocar como servidor DNS: 2001:db8:1:1::1
b) Ubicarse en un cliente y realizar consultar DNS de hosts solo con direcciones IPv4 (registros A). Por ejemplo:
root@ubuntu-VirtualBox:~# dig ipv4.google.com aaaa @2001:db8:1:1::1
; <<>> DiG 9.8.0-P4 <<>> ipv4.google.com aaaa @2001:db8:1:1::1
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- 64252="64252" br="br" id:="id:" noerror="noerror" opcode:="opcode:" query="query" status:="status:">;; flags: qr rd ra; QUERY: 1, ANSWER: 7, AUTHORITY: 4, ADDITIONAL: 0
;; QUESTION SECTION:
;ipv4.google.com. IN AAAA
;; ANSWER SECTION:
ipv4.google.com. 0 IN CNAME ipv4.l.google.com.
ipv4.l.google.com. 300 IN AAAA 2001:db8:1:ffff::4a7d:8268
ipv4.l.google.com. 300 IN AAAA 2001:db8:1:ffff::4a7d:8269
ipv4.l.google.com. 300 IN AAAA 2001:db8:1:ffff::4a7d:826a
ipv4.l.google.com. 300 IN AAAA 2001:db8:1:ffff::4a7d:8293
ipv4.l.google.com. 300 IN AAAA 2001:db8:1:ffff::4a7d:8263
ipv4.l.google.com. 300 IN AAAA 2001:db8:1:ffff::4a7d:8267
;; AUTHORITY SECTION:
google.com. 171975 IN NS ns1.google.com.
google.com. 171975 IN NS ns4.google.com.
google.com. 171975 IN NS ns2.google.com.
google.com. 171975 IN NS ns3.google.com.
;; Query time: 219 msec
;; SERVER: 2001:db8:1:1::1#53(2001:db8:1:1::1)
;; WHEN: Wed Jan 2 16:11:57 2013
;; MSG SIZE rcvd: 294
Nota: La parte a destacar en esta salida son las direcciones IPv6 que comienzan por: 2001:db8:1:ffff..., ya en este momento sabemos que DNS64 esta funcionando.
Ahora NAT64
1) Utilizamos Tayga. El sitio oficial y link para descargarlo se encuentra en: http://www.litech.org/tayga/
2) Lo descomprimimos y desempaquetamos:
#tar -jxvf tayga-0.9.2.tar.bz2
#cd tayga-0.9.2
#./configure
#make
#make install
3) Creamos el directorio donde Tayga guardará los logs:
#mkdir /var/log/tayga
4) Editamos el archivo /usr/local/etc/tayga.conf
y copiamos y pegamos:
tun-device nat64
ipv4-addr 192.168.255.1
prefix 2001:db8:1:ffff::/96
dynamic-pool 192.168.255.0/24
data-dir /var/log/tayga
Tayga es stateless y realiza un nat 1:1 entre IPv6 e IPv4. En la configuración anterior a cada cliente IPv6 se le asignará un IP del pool 192.168.255.0/24; por ello si tenemos más de 255 hosts será necesario utililzar un pool más grande que /24. En caso de que tengas IPv4 públicas suficientes puede ser útil para evitar un doble NAT IPv4.
La directiva prefix indica el prefijo que utilizará Tayga para reconocer los 32 bits de IPv4, es decir, cuando el destino IPv6 sea: 2001:db8:1:ffff::/96, Tayga tomará los ultimos 32 bits para reconocer que ese es el destino IPv4
5) Habilitar routing IPv6 e IPv4 en el servidor.
#echo "1" > /proc/sys/net/ipv6/conf/all/forwarding
#echo "1" > /proc/sys/net/ipv4/ip_forward
6) Creación y configuración de la interfaz nat64:
#tayga --mktun
#ip link set nat64 up
#ip addr add 192.168.124.107 dev nat64
#ip addr add 2001:db8:1::1 dev nat64
(estos comandos crean la interfaz nat64 con las direcciones ip 192.168.0.1/32 y 2001:db8:1::1/128, como dije anteriormente no importa que se solape con los IPs de eth1).
Para revisar:
root@aacosta-ThinkPad-E420:~# ifconfig nat64
nat64 Link encap:UNSPEC HWaddr 00-00-00-00-00-00-00-00-00-00-00-00-00-00-00-00
inet addr:192.168.0.1 P-t-P:192.168.0.1 Mask:255.255.255.255
inet6 addr: 2001:db8:1::1/128 Scope:Global
UP POINTOPOINT RUNNING NOARP MULTICAST MTU:1500 Metric:1
RX packets:2393 errors:0 dropped:0 overruns:0 frame:0
TX packets:2395 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:500
RX bytes:1615556 (1.6 MB) TX bytes:1614316 (1.6 MB)
7) Creación de rutas:
#ip route add 192.168.255.0/24 dev nat64
#ip route add 2001:db8:1:ffff::/96 dev nat64
8) Ejecutamos Tayga
#tayga -d
(el -d es opcional, solo es para tener más información)
PROBAR NAT64
a) Probamos que todo este bien (el ping debe ser satisfactorio):
root@aacosta-ThinkPad-E420:~# ping6 2001:db8:1:ffff::192.168.0.1
PING 2001:db8:1:ffff::192.168.0.1(2001:db8:1:ffff::c0a8:1) 56 data bytes
64 bytes from 2001:db8:1:ffff::c0a8:1: icmp_seq=109 ttl=63 time=2.18 ms
64 bytes from 2001:db8:1:ffff::c0a8:1: icmp_seq=110 ttl=63 time=0.209 ms
64 bytes from 2001:db8:1:ffff::c0a8:1: icmp_seq=111 ttl=63 time=0.190 ms
64 bytes from 2001:db8:1:ffff::c0a8:1: icmp_seq=112 ttl=63 time=0.126 ms
b) Realizamos NAT con la interfaz IPv4 saliente (solo si el pool IPv4 en Tayga es privado):
#iptables -t nat -A POSTROUTING -o eth0 -j MASQUERADE
#iptables -A FORWARD -i eth0 -o nat64 -m state --state RELATED,ESTABLISHED -j ACCEPT
#iptables -A FORWARD -i nat64 -o eth0 -j ACCEPT
c) Ahora solo debes dirigirte a la máquina cliente y todo debe estar funcionando. Ejemplos de ping y trace:
[root@localhost ~]# traceroute6 www.algo.com -n
traceroute to algo-com-prod-elb-170663297.us-east-1.elb.amazonaws.com (2001:db8:1:ffff::36f3:7ac3) from 2001:db8:1:1::2, 30 hops max, 16 byte packets
1 2001:db8:1:1::1 1.224 ms 3.8 ms 0.352 ms
2 2001:db8:1:ffff::c0a8:ff01 0.787 ms 0.772 ms 0.268 ms
3 2001:db8:1:ffff::c0a8:1 0.76 ms 0.869 ms 0.278 ms
[root@localhost ~]# ping6 www.parmalat.com.ve -n
PING www.parmalat.com.ve(2001:db8:1:ffff::c82f:4f04) 56 data bytes
64 bytes from 2001:db8:1:ffff::c82f:4f04: icmp_seq=1 ttl=56 time=7.30 ms
64 bytes from 2001:db8:1:ffff::c82f:4f04: icmp_seq=2 ttl=56 time=5.82 ms
64 bytes from 2001:db8:1:ffff::c82f:4f04: icmp_seq=3 ttl=56 time=5.93 ms
64 bytes from 2001:db8:1:ffff::c82f:4f04: icmp_seq=4 ttl=56 time=8.38 ms
Puedes ver un estado de las asignaciones de Tayga en: /var/log/tayga/dynamic.map
Voila!... todo debe estar funcionado en este momento!
Mas información:
http://www.litech.org/tayga/
http://www.litech.org/tayga/README-0.9.2
http://kurser.iha.dk/eit/itifn/workshops/vne_workshop_2.html
http://ipvsix.me/?tag=tayga
Notas importantes:
- El DNS64 no funciona cuando la respuesta DNS tenga registros AAAA y A. En realidad no es una eroor porque se asume que el host tiene acceso IPv6 a Internet
- Es importante que el DNS64 y NAT64 compartan el mismo prefijo IPv6 (en el ejemplo de este post 2001:db8:1:ffff::/96.
- Durante todo el post describo el procedimiento utilizando la subred IPv6 2001:db8::/32. Favor notar que esta subred debe ser sustituida por sus redes respectivas (al igual que la información referente a IPv4).
- Pueden utilizar 2001:db8::/32 y va a funcionar igualmente pero sin acceso a destinos a IPv6
- El servidor DNS64 y NAT64 pueden ser diferentes equipos/máquinas
to get detailed information about Managed IT Services visit https://wetheitteam.com
DNS64 y NAT64 son dos tecnología diferentes que comunmente trabajan en conjunto.
DNS64 y NAT64 es ideal para colocar en el borde una red donde unicamente existan host con IPv6, algo cada día es más común sobre todo en el mundo de redes celulares y se gran cantidad de sensores.
En Internet hay mucha información sobre como configurar NAT64 y DNS64, la mayoría dice que muy fácil, otros lo colocan más complicado. En lo personal no conseguí ninguna que explicara paso a paso como hacerlo y adicionalmente que explicara la topología de red donde se estaba configurando.
En este post comienzo instalando DNS64 y luego procedemos con NAT64. Se puede instalar en cualquier orden.
Que se necesita antes de comenzar:
- Una subred IPv6 libre (una /96 esta bien) para realizar el mapeo DNS entre IPv4 e IPv6. Esta misma subred la utilizaremos dentro de Tayga para el NAT64
- Logicamente conectividad IPv6 entre los clientes y el servidor DNS64 y NAT64 (no se requiere IPv4)
Topología:
a) Servidor realizando. Solo tiene una interfaz (eth1)
IPv6: 2001:db8:1:1::/64 (eth1).
IPv4: 192.168.124.107
b) IP de un cliente (eth2):
2001:db8:1:1::2/64
c) Subredes IPv6:
Red que "retorna" el DNS64 2001:db8:1:ffff::/96
Pool de NAT en el NAT64: 2001:db8:1:ffff::/96
(si, son el mismo bloque)
d) Interfaz dns64:
192.168.124.107/32
2001:db8:1::1/128
(correcto!, la IPv6 e IPv4 de eth1 se solapan con interfaz dns64)
Procedimiento de DNS64.
Paso 1:
Instalar BIND9:
#aptitude install bind9
Paso 2:
Configurar /etc/bind/named.conf.options:
a) Asegurar que BIND escuche en IPv6 (recordemos que los clientes van a estar en IPv6)
listen-on-v6 { any; };
b) Permitir consultas desde cualquier IP. Si estas utilizando un servidor público o en producción favor restringir las consultas a tus clientes
allow-query { any; };
c) Realizar el DNS64 con la siguiente directiva.
dns64 2001:db8:1:ffff::/96 {
clients {
any; };
};
La configuración del punto "c" lo que indica es que aquellas consultas DNS de aquellos registros que SOLO tienen tienen registro A (no tienen registro AAAA) serán entregadas a los clientes añadiendo 2001:db8::1:ffff::/96
d) Reiniciar bind9
#/etc.init.d/bind9 restart
Probar DNS64:
a) En un PC cliente colocar como servidor DNS: 2001:db8:1:1::1
b) Ubicarse en un cliente y realizar consultar DNS de hosts solo con direcciones IPv4 (registros A). Por ejemplo:
root@ubuntu-VirtualBox:~# dig ipv4.google.com aaaa @2001:db8:1:1::1
; <<>> DiG 9.8.0-P4 <<>> ipv4.google.com aaaa @2001:db8:1:1::1
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- 64252="64252" br="br" id:="id:" noerror="noerror" opcode:="opcode:" query="query" status:="status:">;; flags: qr rd ra; QUERY: 1, ANSWER: 7, AUTHORITY: 4, ADDITIONAL: 0
;; QUESTION SECTION:
;ipv4.google.com. IN AAAA
;; ANSWER SECTION:
ipv4.google.com. 0 IN CNAME ipv4.l.google.com.
ipv4.l.google.com. 300 IN AAAA 2001:db8:1:ffff::4a7d:8268
ipv4.l.google.com. 300 IN AAAA 2001:db8:1:ffff::4a7d:8269
ipv4.l.google.com. 300 IN AAAA 2001:db8:1:ffff::4a7d:826a
ipv4.l.google.com. 300 IN AAAA 2001:db8:1:ffff::4a7d:8293
ipv4.l.google.com. 300 IN AAAA 2001:db8:1:ffff::4a7d:8263
ipv4.l.google.com. 300 IN AAAA 2001:db8:1:ffff::4a7d:8267
;; AUTHORITY SECTION:
google.com. 171975 IN NS ns1.google.com.
google.com. 171975 IN NS ns4.google.com.
google.com. 171975 IN NS ns2.google.com.
google.com. 171975 IN NS ns3.google.com.
;; Query time: 219 msec
;; SERVER: 2001:db8:1:1::1#53(2001:db8:1:1::1)
;; WHEN: Wed Jan 2 16:11:57 2013
;; MSG SIZE rcvd: 294
Nota: La parte a destacar en esta salida son las direcciones IPv6 que comienzan por: 2001:db8:1:ffff..., ya en este momento sabemos que DNS64 esta funcionando.
Ahora NAT64
1) Utilizamos Tayga. El sitio oficial y link para descargarlo se encuentra en: http://www.litech.org/tayga/
2) Lo descomprimimos y desempaquetamos:
#tar -jxvf tayga-0.9.2.tar.bz2
#cd tayga-0.9.2
#./configure
#make
#make install
3) Creamos el directorio donde Tayga guardará los logs:
#mkdir /var/log/tayga
4) Editamos el archivo /usr/local/etc/tayga.conf
y copiamos y pegamos:
tun-device nat64
ipv4-addr 192.168.255.1
prefix 2001:db8:1:ffff::/96
dynamic-pool 192.168.255.0/24
data-dir /var/log/tayga
Tayga es stateless y realiza un nat 1:1 entre IPv6 e IPv4. En la configuración anterior a cada cliente IPv6 se le asignará un IP del pool 192.168.255.0/24; por ello si tenemos más de 255 hosts será necesario utililzar un pool más grande que /24. En caso de que tengas IPv4 públicas suficientes puede ser útil para evitar un doble NAT IPv4.
La directiva prefix indica el prefijo que utilizará Tayga para reconocer los 32 bits de IPv4, es decir, cuando el destino IPv6 sea: 2001:db8:1:ffff::/96, Tayga tomará los ultimos 32 bits para reconocer que ese es el destino IPv4
5) Habilitar routing IPv6 e IPv4 en el servidor.
#echo "1" > /proc/sys/net/ipv6/conf/all/forwarding
#echo "1" > /proc/sys/net/ipv4/ip_forward
6) Creación y configuración de la interfaz nat64:
#tayga --mktun
#ip link set nat64 up
#ip addr add 192.168.124.107 dev nat64
#ip addr add 2001:db8:1::1 dev nat64
(estos comandos crean la interfaz nat64 con las direcciones ip 192.168.0.1/32 y 2001:db8:1::1/128, como dije anteriormente no importa que se solape con los IPs de eth1).
Para revisar:
root@aacosta-ThinkPad-E420:~# ifconfig nat64
nat64 Link encap:UNSPEC HWaddr 00-00-00-00-00-00-00-00-00-00-00-00-00-00-00-00
inet addr:192.168.0.1 P-t-P:192.168.0.1 Mask:255.255.255.255
inet6 addr: 2001:db8:1::1/128 Scope:Global
UP POINTOPOINT RUNNING NOARP MULTICAST MTU:1500 Metric:1
RX packets:2393 errors:0 dropped:0 overruns:0 frame:0
TX packets:2395 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:500
RX bytes:1615556 (1.6 MB) TX bytes:1614316 (1.6 MB)
7) Creación de rutas:
#ip route add 192.168.255.0/24 dev nat64
#ip route add 2001:db8:1:ffff::/96 dev nat64
8) Ejecutamos Tayga
#tayga -d
(el -d es opcional, solo es para tener más información)
PROBAR NAT64
a) Probamos que todo este bien (el ping debe ser satisfactorio):
root@aacosta-ThinkPad-E420:~# ping6 2001:db8:1:ffff::192.168.0.1
PING 2001:db8:1:ffff::192.168.0.1(2001:db8:1:ffff::c0a8:1) 56 data bytes
64 bytes from 2001:db8:1:ffff::c0a8:1: icmp_seq=109 ttl=63 time=2.18 ms
64 bytes from 2001:db8:1:ffff::c0a8:1: icmp_seq=110 ttl=63 time=0.209 ms
64 bytes from 2001:db8:1:ffff::c0a8:1: icmp_seq=111 ttl=63 time=0.190 ms
64 bytes from 2001:db8:1:ffff::c0a8:1: icmp_seq=112 ttl=63 time=0.126 ms
b) Realizamos NAT con la interfaz IPv4 saliente (solo si el pool IPv4 en Tayga es privado):
#iptables -t nat -A POSTROUTING -o eth0 -j MASQUERADE
#iptables -A FORWARD -i eth0 -o nat64 -m state --state RELATED,ESTABLISHED -j ACCEPT
#iptables -A FORWARD -i nat64 -o eth0 -j ACCEPT
c) Ahora solo debes dirigirte a la máquina cliente y todo debe estar funcionando. Ejemplos de ping y trace:
[root@localhost ~]# traceroute6 www.algo.com -n
traceroute to algo-com-prod-elb-170663297.us-east-1.elb.amazonaws.com (2001:db8:1:ffff::36f3:7ac3) from 2001:db8:1:1::2, 30 hops max, 16 byte packets
1 2001:db8:1:1::1 1.224 ms 3.8 ms 0.352 ms
2 2001:db8:1:ffff::c0a8:ff01 0.787 ms 0.772 ms 0.268 ms
3 2001:db8:1:ffff::c0a8:1 0.76 ms 0.869 ms 0.278 ms
[root@localhost ~]# ping6 www.parmalat.com.ve -n
PING www.parmalat.com.ve(2001:db8:1:ffff::c82f:4f04) 56 data bytes
64 bytes from 2001:db8:1:ffff::c82f:4f04: icmp_seq=1 ttl=56 time=7.30 ms
64 bytes from 2001:db8:1:ffff::c82f:4f04: icmp_seq=2 ttl=56 time=5.82 ms
64 bytes from 2001:db8:1:ffff::c82f:4f04: icmp_seq=3 ttl=56 time=5.93 ms
64 bytes from 2001:db8:1:ffff::c82f:4f04: icmp_seq=4 ttl=56 time=8.38 ms
Puedes ver un estado de las asignaciones de Tayga en: /var/log/tayga/dynamic.map
Voila!... todo debe estar funcionado en este momento!
Mas información:
http://www.litech.org/tayga/
http://www.litech.org/tayga/README-0.9.2
http://kurser.iha.dk/eit/itifn/workshops/vne_workshop_2.html
http://ipvsix.me/?tag=tayga
Notas importantes:
- El DNS64 no funciona cuando la respuesta DNS tenga registros AAAA y A. En realidad no es una eroor porque se asume que el host tiene acceso IPv6 a Internet
- Es importante que el DNS64 y NAT64 compartan el mismo prefijo IPv6 (en el ejemplo de este post 2001:db8:1:ffff::/96.
- Durante todo el post describo el procedimiento utilizando la subred IPv6 2001:db8::/32. Favor notar que esta subred debe ser sustituida por sus redes respectivas (al igual que la información referente a IPv4).
- Pueden utilizar 2001:db8::/32 y va a funcionar igualmente pero sin acceso a destinos a IPv6
- El servidor DNS64 y NAT64 pueden ser diferentes equipos/máquinas
to get detailed information about Managed IT Services visit https://wetheitteam.com
Suscribirse a:
Entradas (Atom)
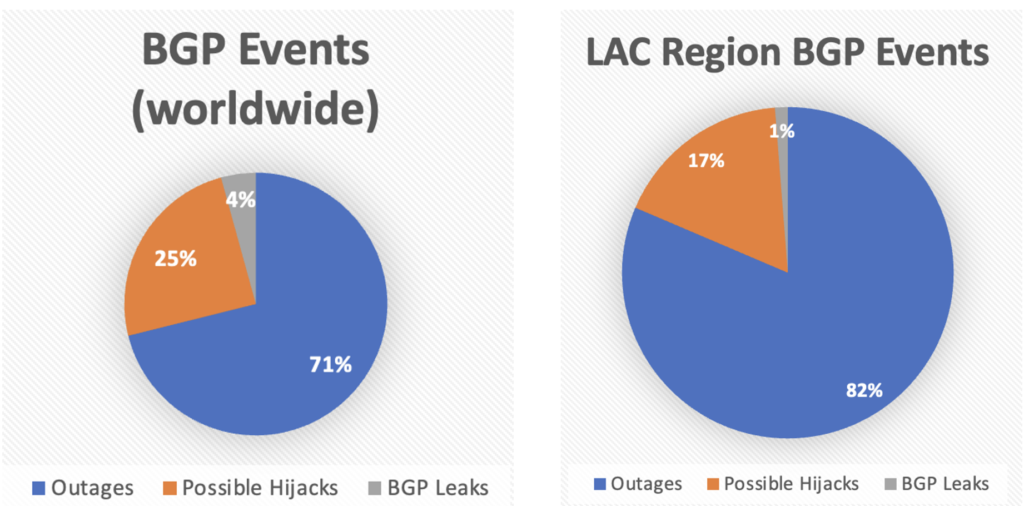
BGP Stream: un año de análisis sobre incidentes BGP
BGP Stream: un año de análisis sobre incidentes BGP 04/03/2024 Por Alejandro Acosta , Coordinador de I+D en LACNIC LACNIC presenta la prim...