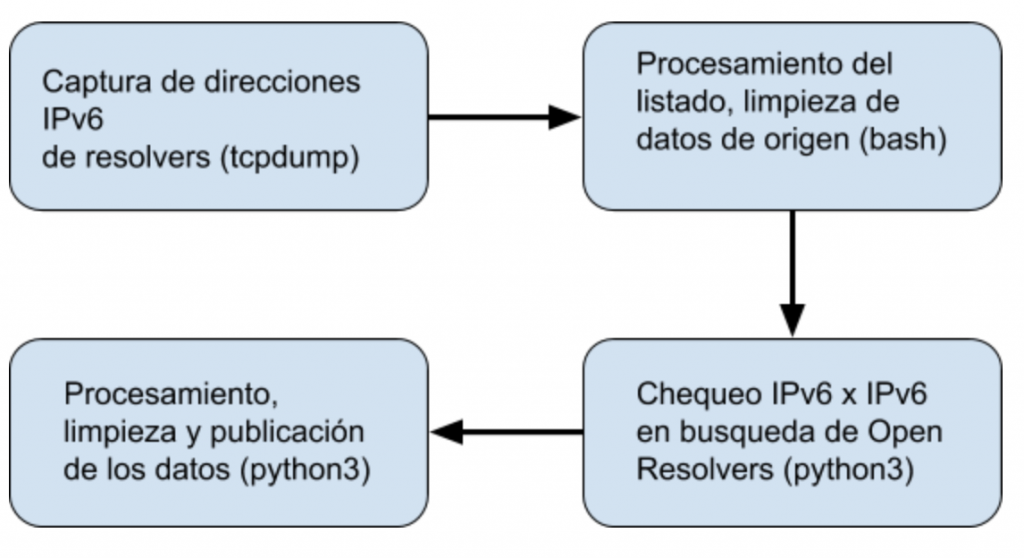
En mi vida, al igual que muchas personas, tengo varias pasiones: familia, trabajo, deporte; y en este último incluyo el hermoso juego del dominó. Hace unos 25 años alcancé mi mejor nivel en este juego, participé de varios torneos (ganando algunos pocos) y la guinda de la corona, obtuve un 6to lugar en un torneo nacional. Adicionalmente, menciono que vengo de una familia con alguna herencia de fanáticos del dominó, como lo eran dos tíos, mi padre y mi hermano.
Jugar dominó es una de las cosas más lindas entre familia, amigos y no tan amigos. Ahora bien, ¿en qué se parece el juego del dominó al protocolo TCP/IP? Alguno quizás ya debe estar pensando “Alejandro ahora sí se volvió loco”; quizás no me volví loco, probablemente ya lo estaba.
Pero ese no es el punto, te demostraré que TCP/IP y el dominó tienen mucho en común.
Los protocolos TCP/IP según IBM [1] lo definen como:
“Los protocolos son conjuntos de normas para formatos de mensaje y procedimientos que permiten a las máquinas y los programas de aplicación intercambiar información. Cada máquina implicada en la comunicación debe seguir estas normas para que el sistema principal de recepción pueda interpretar el mensaje.”
Suena interesante…, pero probablemente aún no veas qué tiene que ver con el dominó, y sigues pensando que es una locura. ¡A no desesperar, ya vamos a llegar!
Y el Dominó (según chatgpt):
“El juego de dominó es un juego de mesa en el que los jugadores utilizan fichas con números en ambos extremos para colocarlas en un tablero. El objetivo del juego es colocar todas las fichas antes que los demás jugadores. La comunicación entre los jugadores en el juego de dominó se basa en la estrategia y en la planificación. Los jugadores deben comunicar qué fichas tienen y qué fichas pueden jugar, y deben trabajar juntos para encontrar la mejor manera de colocar las fichas en el tablero. Además, los jugadores deben estar atentos a las jugadas de los demás jugadores y adaptar su estrategia en consecuencia. En resumen, la comunicación en el juego de dominó es esencial para el éxito del equipo y para ganar el juego.”
Ahora, pensemos un poco macro, a estas alturas podemos apreciar que en ambos hay piezas que deben ser enviadas/jugadas, y las mismas deben mantener un orden para poder alcanzar una comunicación exitosa. Además, en ambos hay estrategia y planificación para lograr el objetivo, en uno se conectan las piezas y en el otro dispositivos, ¿ya comencé a convencerte?
Ahora hablemos de comunicación y el Dominó en parejas, y es aquí donde está el corazón del tema al que quiero llegar.
Independiente del estilo de dominó que cada uno juegue (Cubano, Latino, Méxicano, Chileno, etc) “el dominó en parejas” es un juego de comunicación, no es diferente a una red de datos. Un jugador tiene que comunicarse con su pareja (A → B, B → A) para indicarle qué piezas tiene o no.
Igualmente, ¿cómo me comunico si una de las reglas es no poder hablar?. Allí está la grandeza de los buenos jugadores, al igual que TCP/IP -y cualquier otro protocolo de comunicación- hay que seguir ciertas reglas.
Luego de mis tres décadas de experiencia en ambos mundos, aquí les dejo lo que considero los principales jugadas en el ecosistema del dominó en parejas y su contraparte en TCP/IP:
La salida en el dominó
La salida en el dominó (primera pieza que coloca el salidor) es idéntica a un SYN Packet de TCP (y más específicamente es un SYN con payload al estilo TCP Fast Open). Esta es una comparación hermosa, porque la salida en el dominó por parejas *siempre* lleva información, generalmente se refiere al palo (número) que uno más desea. TCP Fast Open (una lindura del mundo de TCP) se encuentra definido en el RFC 7413 y su principal objetivo es poder enviar información en el primer paquete con en el que comienza toda comunicación TCP (SYN)
La pensada (double ACK)
Se considera payload no necesario en algunas redes pero puede valer la pena. La “pensada” de un jugador indica explícitamente que el jugador tiene más de una pieza del “palo” (número) jugado; con ello, el jugador está comunicando eficientemente información a su compañero quien debe darse notar estas pensadas, es muy similar a aquellos servidores y redes donde se configuran dispositivos para enviar más de un ACK en TCP (acuso de recibo)
Pasar (packet dropped)
En TCP al perder un paquete se entra en la fase de “Congestion Avoidance”, allí disminuye en un 50% la ventana TCP y por ende la velocidad de transmisión. Nada más similar al pasar en dominó; claro, aquí se entra en etapa de pánico, sobre todo cuando hay mucho que transmitir.
La versión
En el mundo de IP estamos acostumbrados a IPv4 e IPv6, en el dominó la única diferencia es que la versión va del 0 (blancas) al 6. (si, si, ciertamente existen Dominoes hasta 9, toda regla tiene su excepción ;-)
Pensar en falso
TCP Half-Open, ¿se recuerdan?, es cuando en el saludo de tres vías (SYN, SYN+ACK, ACK) se queda en la mitad del saludo (ojo, este es el concepto moderno, en honor a la verdad no respeta RFC 793). También es comúnmente utilizado para realizar ataques de DoS.
Tamaño de la carga (Total Length)
Cuando vamos levantando nuestras fichas en dominó, ¿cuántos -puntos- cargué?.
La dirección origen y el destino
Aquí nos encontramos específicamente en el mundo de capa 3. Este es un caso muy interesante donde, al igual que en redes de comunicación, un host se comunica con algún otro. Lo mismo sucede en el dominó, es decir, algunos paquetes pueden ir orientados al compañero; sin embargo, en algunos casos se puede orientar a los oponentes según la necesidad (ejemplo, cuando se busca “tal palo”).
Pensar en cada jugada
Bufferbloat es una situación muy particular pero a su vez ocurre con mucha frecuencia. Básicamente son situaciones donde los hosts (principalmente middlewares al estilo, routers, firewalls, Switches) agregan delay (cargando los buffers) al momento de conmutar los paquetes. Lo anterior crea latencia y jitters innecesarios. Por favor, si administras redes no dejes de revisar si sufres de bufferbloat..
Trancar la partida/mano
Es el momento donde ya es imposible jugar alguna pieza de dominó, y en TCP/IP supone la caída de la red, por lo que tampoco se puede enviar ningún paquete.
Consecuencias de la buena y mala comunicación
En dominó en pareja, al igual que en cualquier protocolo de red, comunicarse bien o mal trae sus consecuencias. Si uno tiene buena comunicación en el dominó alcanzará -muy seguramente- la victoria. Si la comunicación *no* es buena, el resultado será la pérdida del partido. En TCP/IP si la comunicación es buena se establecerá la conexión correctamente y se entregarán los datos. Si la comunicación es mala, obtendremos datos corruptos y/o el no establecimiento de la conexión.
Doble Cabeza
En el dominó se entiende que tienes doble cabeza cuando llevas la última pieza de dos números diferentes. ¿Con qué se puede comparar? Con TCP Multipath (MPTCP), definido en el RFC 8684.que permite operar conexiones por diferentes caminos. Es por ello que MPTCP ofrece redundancia y eficiencia en el ancho de banda a consumir.
¿Aún no los convencí? Bueno, tengo una oportunidad más a ver si lo logro.
A continuación les presento un modelo capa a capa entre TCP/IP vs dominó
| Modelo TCP/IP (+ capa de usuario) | Modelo Dominó |
| Usuario | Jugador |
| Aplicación | Construir la jugada |
| Transporte | Seleccionar la ficha/piedra |
| Red | Tomar las piedras |
| Enlace | Piedras/Fichas |
| Física | Colocar en la mesa la ficha |
Un paquete en el modelo TCP/IP se construye desde las capas superiores a las inferiores (posteriormente se inyecta a la red, etc), lo recibe el host destino y lo procesa “a la inversa”, desde la capa física hasta la aplicación. En el modelo dominó, ocurre exactamente igual: el jugador arma su jugada, selecciona su ficha/piedra, la toma para luego inyectarla en el juego.
Conclusión
La comparación entre el juego de dominó en parejas y el protocolo de comunicación TCP/IP puede parecer extraña al principio. Sin embargo, si observamos con atención, podemos encontrar similitudes, En el dominó existen dos jugadores que actúan como emisores y receptores de información, ya que cada uno tiene su propio conjunto de fichas y deben comunicarse entre sí para decidir qué ficha jugar en cada turno. Del mismo modo, en TCP/IP existen dispositivos que actúan como emisores y receptores de información.
Estos contrastes ilustran cómo a menudo pueden existir similitudes entre sistemas aparentemente disímiles, y que comprender estas semejanzas pueden ser útiles para entender conceptos complejos y ver las cosas desde una perspectiva diferente.